Standaardafwijking is de maatstaf voor de spreiding van statistieken. De standaardafwijkingsformule wordt gebruikt om de afwijking van de gegevenswaarde van de gemiddelde waarde te vinden, dat wil zeggen dat deze wordt gebruikt om de spreiding van alle waarden in een gegevensset naar de gemiddelde waarde te vinden. Er zijn verschillende standaardafwijkingsformules om de standaardafwijking van een willekeurige variabele te berekenen.
In dit artikel zullen we meer te weten komen wat is standaardafwijking, de standaardafwijkingsformules, hoe standaardafwijking te berekenen en voorbeelden van standaardafwijking in detail.
Inhoudsopgave
- Wat is standaarddeviatie?
- Standaardafwijkingsformule
- Hoe standaarddeviatie berekenen?
- Wat is variantie
- Variantieformule
- Hoe variantie berekenen?
- Standaardafwijking van niet-gegroepeerde gegevens
- Standaardafwijking van discrete gegroepeerde gegevens
- Standaardafwijking van continu gegroepeerde gegevens
- Standaardafwijking van de waarschijnlijkheidsverdeling
- Standaardafwijking van willekeurige variabelen
- Standaardafwijkingsformule Excel
- Statistieken van standaarddeviatieformules
Wat is standaarddeviatie?
Standaarddeviatie wordt gedefinieerd als de mate van spreiding van het datapunt ten opzichte van de gemiddelde waarde van het datapunt. Het vertelt ons hoe de waarde van de datapunten varieert ten opzichte van de gemiddelde waarde van het datapunt en het vertelt ons over de variatie van het datapunt in de steekproef van de gegevens.
De standaarddeviatie van een bepaalde steekproef van een dataset wordt ook gedefinieerd als de vierkantswortel van de variantie van de dataset. Gemiddelde afwijking van de n-waarden (zeg x1, X2, X3, …, XN) wordt berekend door de som van de kwadraten te nemen van het verschil tussen elke waarde en het gemiddelde, d.w.z.
Gemiddelde afwijking = 1/n∑ i N (X i - X) 2
Gemiddelde afwijking wordt gebruikt om ons iets te vertellen over de spreiding van de gegevens. De lagere mate van afwijking vertelt ons dat de waarnemingen xi dicht bij de gemiddelde waarde liggen en de depressie laag is, terwijl de hogere mate van afwijking ons vertelt dat de waarnemingen xi ver van de gemiddelde waarde liggen en de spreiding hoog is.
machine learning en typen
Definitie van standaardafwijking
Standaarddeviatie is een maatstaf die in statistieken wordt gebruikt om te begrijpen hoe de gegevenspunten in een set zijn verspreid vanuit de gemeen waarde. Het geeft de omvang van de variatie van de gegevens aan en laat zien hoe ver individuele gegevenspunten afwijken van het gemiddelde.
Rekening: Hoe vind ik de standaarddeviatie in de statistiek?
Standaardafwijkingsformule
Standaarddeviatie wordt gebruikt om de spreiding van de statistische gegevens te meten. Het vertelt ons hoe de statistische gegevens zijn verspreid. Formule om de standaardafwijking te berekenen wordt gebruikt om de afwijking van alle datasets ten opzichte van de gemiddelde positie te vinden. Het kan zijn dat u vragen heeft over de standaardafwijking, hoe u deze moet berekenen of hoe je een standaarddeviatie berekent . Er zijn twee standaardafwijkingsformules die worden gebruikt om de standaardafwijking van een bepaalde gegevensset te vinden. Zij zijn,
- Formule voor standaarddeviatie van populatie
- Voorbeeld van standaardafwijkingsformule
waar,
- s is de populatiestandaarddeviatie
- X i ben ik e observatie
- x̄ is het steekproefgemiddelde
- N is het aantal waarnemingen
waar,
- σ is de populatiestandaarddeviatie
- Xiben ikeObservatie
- μ is het populatiegemiddelde
- N is het aantal waarnemingen
Het is duidelijk dat beide formules er hetzelfde uitzien en alleen schuifveranderingen in hun noemer hebben. Noemer in het geval van het monster is n-1 maar in het geval van de bevolking is N. Aanvankelijk was de noemer in de standaarddeviatie van de steekproef formule heeft N in de noemer, maar het resultaat van deze formule was niet passend. Er is dus een correctie aangebracht en de n wordt vervangen door n-1. Deze correctie wordt de correctie van Bessel genoemd die op hun beurt de meest passende resultaten opleverden.
Lees verder: Verschil tussen variantie en standaarddeviatie
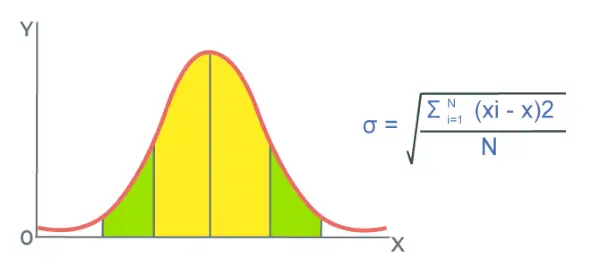
Formule voor het berekenen van de standaardafwijking
De formule die wordt gebruikt voor het berekenen van de standaarddeviatie wordt besproken in de onderstaande afbeelding,

Hoe standaarddeviatie berekenen?
Over het algemeen hebben we het over standaarddeviatie standaarddeviatie van de populatie . De stappen om de standaardafwijking van een gegeven reeks waarden te berekenen zijn als volgt:
Stap 1: Bereken het observatiegemiddelde met behulp van de formule
(Gemiddelde = som van waarnemingen/aantal waarnemingen)
Stap 2: Bereken kwadratische verschillen tussen gegevenswaarden en het gemiddelde.
(Gegevenswaarde – Gemiddelde)2
Stap 3: Bereken het gemiddelde van de gekwadrateerde verschillen.
(Variantie = som van gekwadrateerde verschillen / aantal waarnemingen)
Stap 4: Bereken de vierkantswortel van de variantie, dit geeft de standaarddeviatie.
(Standaardafwijking = √Variantie)
Wat is variantie
Variantie vertelt ons in feite hoe verspreid een reeks gegevens is. Als alle gegevenspunten hetzelfde zijn, is de variantie nul. Elke variantie die niet nul is, wordt als positief beschouwd . Lage variantie betekent dat de gegevenspunten dicht bij het gemiddelde (of gemiddelde) en bij elkaar liggen. Hoge variantie betekent dat de gegevenspunten ten opzichte van het gemiddelde en ten opzichte van elkaar verspreid zijn. Simpel gezegd is variantie het gemiddelde van hoe ver elk datapunt verwijderd is van het gemiddelde, in het kwadraat.
Verschil tussen variantie en afwijking
| Aspect | Variantie | Afwijking (standaardafwijking) |
|---|---|---|
| Definitie | Maatstaf voor spreiding in een dataset. | Maatstaf voor de gemiddelde afstand tot het gemiddelde. |
| Berekening | Gemiddelde van kwadratische verschillen met het gemiddelde. | Vierkantswortel van de variantie. |
| Symbool | σ^2 (sigmakwadraat) | σ (sigma) |
| Interpretatie | Geeft de gemiddelde kwadratische afwijking van gegevenspunten van het gemiddelde aan. | Geeft de gemiddelde afstand van gegevenspunten tot het gemiddelde aan. |
Rekening:
- Verschil tussen variantie en standaarddeviatie
- Gemiddelde, variantie en standaarddeviatie
Variantieformule
De formule om de variantie van een dataset te berekenen is als volgt:
Variantie (σ^2) = Σ [(x – μ)^2] / N
Waar:
- Σ staat voor sommatie (optellen)
- x vertegenwoordigt elk afzonderlijk gegevenspunt
- μ (mu) is het gemiddelde (gemiddelde) van de dataset
- N is het totale aantal gegevenspunten
Hoe variantie berekenen?
De stappen om de variantie van een dataset te berekenen:
Stap 1: Bereken het gemiddelde (gemiddelde):
Tel alle waarden in de gegevensset bij elkaar op en deel deze door het totale aantal waarden. Dit geeft je het gemiddelde (μ).
Gemiddelde (μ) = (som van alle waarden) / (totaal aantal waarden)
Stap 2: Zoek de kwadratische verschillen met het gemiddelde:
Voor elke waarde in de gegevensset trekt u het in de eerste stap berekende gemiddelde van die waarde af en kwadrateert u het resultaat. Dit geeft u het kwadraat van het verschil voor elke waarde.
Kwadratisch verschil voor elke waarde = (Waarde – Gemiddelde)^2
Stap 3: Bereken het gemiddelde van de gekwadrateerde verschillen:
Tel alle kwadratische verschillen op die in de vorige stap zijn berekend en deel deze vervolgens door het totale aantal waarden in de gegevensset. Dit geeft je de variantie (σ^2).
Variantie (σ^2) = (Som van alle gekwadrateerde verschillen) / (Totaal aantal waarden)
Rekening: Variantie en standaarddeviatie
Standaardafwijking van niet-gegroepeerde gegevens
Aangenomen gemiddelde methode
Standaardafwijking volgens werkelijke gemiddelde methode
Bij de standaardafwijking volgens de werkelijke gemiddelde-methode wordt de basisgemiddeldeformule gebruikt om het gemiddelde van de gegeven gegevens te berekenen en met behulp van deze gemiddelde waarde ontdekken we de standaardafwijking van de gegeven gegevenswaarden. We berekenen het gemiddelde in deze methode met de formule,
μ = (Som van waarnemingen)/(Aantal waarnemingen)
En vervolgens wordt de standaardafwijking berekend met behulp van de standaardafwijkingsformule.
σ = √(∑ i N (X i - X) 2 /N)
Voorbeeld: Zoek standaarddeviatie van dataset. X = {2, 3, 4, 5, 6}
Oplossing:
Gegeven,
- n = 5
- Xi= {2, 3, 4, 5, 6}
Wij weten,
Gemiddelde (μ) = (Som van waarnemingen)/(Aantal waarnemingen)
⇒ μ = (2 + 3 + 4 + 5 + 6)/ 5
⇒ μ = 4
P2= ∑iN(Xi- X)2/N
⇒ blz2= 1/n[(2 – 4)2+ (3 – 4)2+ (4 – 4)2+ (5 – 4)2+ (6 – 4)2]
⇒ blz2= 10/5 = 2
Dus σ = √(2) = 1,414
Standaardafwijking volgens de veronderstelde gemiddelde methode
Voor zeer grote waarden van x is het vinden van het gemiddelde van de gegroepeerde gegevens een vervelende taak, dus gingen we uit van een willekeurige waarde (A) als gemiddelde waarde en berekenden we vervolgens de standaarddeviatie met behulp van de normale methode. Stel dat voor de groep van n gegevenswaarden ( x1, X2, X3, …, XN), het veronderstelde gemiddelde is A, dan is de afwijking:
D i = x i - A
Nu, aangenomen gemiddelde formule is,
σ = √(∑ i N (D i ) 2 /N)
Standaardafwijking per stapafwijkingsmethode
We kunnen ook de standaardafwijking van de gegroepeerde gegevens berekenen met behulp van de stapafwijkingsmethode. Net als bij de bovenstaande methode kiezen we ook bij deze methode een willekeurige gegevenswaarde als verondersteld gemiddelde (zeg A). Vervolgens berekenen we de afwijkingen van alle gegevenswaarden (x 1 , X 2 , X 3 , …, X N ), D i = x i - A
In de volgende stap, we berekenen de stapafwijkingen (d ') met behulp van
d’ = d/i
waar ' i ‘ is een gemeenschappelijke factor van alle ‘d’-waarden
Dan, standaardafwijkingsformule is,
σ = √[(∑(d’) 2 /n) – (∑d’n) 2 ] × ik
waar ' N ' is het totale aantal gegevenswaarden
Standaardafwijking van discrete gegroepeerde gegevens
In gegroepeerde gegevens hebben we eerst een frequentietabel gemaakt en daarna zijn er verdere berekeningen gemaakt. Voor discrete gegroepeerde gegevens kan de standaardafwijking ook worden berekend met behulp van drie methoden:
- Werkelijke gemiddelde methode
- Aangenomen gemiddelde methode
- Stapafwijkingsmethode
Standaardafwijkingsformule gebaseerd op discrete frequentieverdeling
Als een gegeven dataset n waarden heeft (x1, X2, X3, …, XN) en de frequentie die daarmee overeenkomt is (f1, F2, F3, …, FN) dan wordt de standaardafwijking berekend met behulp van de formule,
σ = √(∑ i N F i (X i - X) 2 /N)
waar,
- N is de totale frequentie (n = f1+ f2+ f3+…+ vN)
- X is het gemiddelde van de gegevens
Voorbeeld: Bereken de standaardafwijking voor de gegeven gegevens
Xi | Fi |
|---|---|
| 10 | 1 |
| 4 | 3 |
| 6 | 5 |
| 8 | 1 |
Oplossing:
Gemiddelde (x̄) = ∑(fiXi)/∑(vi)
⇒ Gemiddelde (μ) = (10×1 + 4×3 + 6×5 + 8×1)/(1+3+5+1)
⇒ Gemiddelde (μ) = 60/10 = 6
n = ∑(fi) = 1+3+5+1 = 10
| Xi | Fi | FiXi | (Xi- X) | (Xi- X)2 | Fi(Xi- X)2 |
|---|---|---|---|---|---|
| 10 | 1 | 10 | 4 | 16 | 16 |
| 4 | 3 | 12 | -2 | 4 | 12 |
| 6 | 5 | 30 | 0 | 0 | 0 |
| 8 | 1 | 8 | 2 | 4 | 8 |
Nu,
σ = √(∑ i N F i (X i - X) 2 /N)
⇒ σ = √[(16 + 12 + 0 +8)/10]
⇒ σ = √(3,6) = 1,897
Standaardafleiding (σ) = 1,897
D i = x i - A
De formule voor de standaardafwijking volgens de veronderstelde gemiddelde methode is nu:
σ = √[(∑(f i D i ) 2 /n) – (∑f i D i /N) 2 ]
waar,
- ' F ‘ is frequentie van gegevenswaarde x
- ' N ' is Totale frequentie [n = ∑(f i )]
In de volgende stap, we berekenen de stapafwijkingen (d ') met behulp van
d’ = d/i
waar ' i ‘is de gemeenschappelijke factor van alles’ D ' waarden
Dan, standaardafwijkingsformule is,
σ = √[(∑(fd’) 2 /n) – (�’/n) 2 ] × ik
waar ' N ' is het totale aantal gegevenswaarden
Standaardafwijking van continu gegroepeerde gegevens
Voor de continu gegroepeerde gegevens kunnen we eenvoudig de standaardafwijking berekenen met behulp van de discrete gegevensformules door elke klasse te vervangen door het middelpunt (als xi) en vervolgens normaal gesproken de formules berekenen.
Het middelpunt van elke klasse wordt berekend met behulp van de formule,
X i (Middenpunt) = (Bovengrens + Ondergrens)/2
Bijvoorbeeld, Bereken de standaardafwijking van continu gegroepeerde gegevens zoals weergegeven in de tabel,
| Klas | 0-10 | 10-20 | 20-30 | 30-40 |
|---|---|---|---|---|
Frequentie (bijvi) | 2 | 4 | 2 | 2 |
Werkelijke gemiddelde methode
- Aangenomen gemiddelde methode
- Stapafwijkingsmethode
We kunnen elk van de bovenstaande methoden gebruiken om de standaarddeviatie te vinden. Hier vinden we de standaardafwijking met behulp van de werkelijke gemiddelde methode.
De oplossing voor bovenstaande vraag is:
| Klas | 5-15 | 15-25 | 25-35 | 35-45 |
|---|---|---|---|---|
| Xi | 10 | twintig | 30 | 40 |
Frequentie (bijvi) | 2 | 4 | 2 | 2 |
Gemiddelde (x̄) = ∑(fiXi)/∑(vi)
⇒ Gemiddelde (μ) = (10×2 + 20×4 + 30×2 + 40×2)/(2+4+2+2)
⇒ Gemiddelde (μ) = 240/10 = 24
n = ∑(fi) = 2+4+2+2 = 10
| Xi | Fi | FiXi | (Xi- X) | (Xi- X)2 | Fi(Xi- X)2 |
|---|---|---|---|---|---|
| 10 | 2 | twintig | 14 | 196 | 392 |
| twintig | 4 | 80 | -4 | 16 | 64 |
| 30 | 2 | 60 | 6 | 36 | 72 |
| 40 | 2 | 80 | 16 | 256 | 512 |
Nu,
σ = √(∑ i N F i (X i - X) 2 /N)
⇒ σ = √[(392 + 64 + 72 +512)/10]
⇒ σ = √(104) = 10.198
Standaardafleiding (σ) = 10.198
Op dezelfde manier kunnen ook andere methoden worden gebruikt om de standaardafwijking van continu gegroepeerde gegevens te vinden.
Rekening: Standaardafwijking in individuele series
Standaardafwijking van de waarschijnlijkheidsverdeling
De waarschijnlijkheid van alle mogelijke uitkomsten is over het algemeen gelijk en we doen veel pogingen om de experimentele waarschijnlijkheid van het gegeven experiment te vinden.
- Voor een normale verdeling is het gemiddelde verwachte gemiddelde nul en de standaarddeviatie 1.
- Voor een binominale verdeling wordt de standaardafwijking gegeven door de formule:
σ = √(npq)
waar,
- N is Aantal pogingen
- P is de waarschijnlijkheid van succes van de proef
- Q is de kans op mislukken van de proef (q = 1 – p)
- Voor een Poisson-verdeling wordt de standaardafwijking gegeven door
σ = √λt
waar,
- l is het gemiddelde aantal successen
- T wordt gegeven tijdsinterval
Standaardafwijking van willekeurige variabelen
Willekeurige variabelen zijn de numerieke waarden die de mogelijke uitkomst van het willekeurige experiment in de steekproefruimte aangeven. Het berekenen van de standaarddeviatie van de willekeurige variabele vertelt ons over de waarschijnlijkheidsverdeling van de willekeurige variabele en de mate van verschil met de verwachte waarde.
We gebruiken X, Y en Z als functie om de willekeurige variabelen weer te geven. De waarschijnlijkheid van de willekeurige variabele wordt aangegeven als P(X) en de verwachte waarde wordt aangegeven met het μ-symbool.
Vervolgens wordt de standaardafwijking van de waarschijnlijkheidsverdeling gegeven met behulp van de formule:
σ = √(∑ (x i - M) 2 × P(X)/n)
tekenreeks als een array
Lees verder,
- Gemeen
- Modus
- Gemiddelde afwijking
Voorbeeld van standaardafwijkingsformule
Voorbeeld 1: Zoek de standaardafwijking van de volgende gegevens,
Xi | 5 | 12 | vijftien |
|---|---|---|---|
Fi | 2 | 4 | 3 |
Oplossing:
Maak eerst de tabel als volgt, zodat we de verdere waarden gemakkelijk kunnen berekenen.
Xi | Fi | Xi×fi | Xi- M | (Xi-μ)2 | f×(Xi-M)2 |
|---|---|---|---|---|---|
5 | 2 | 10 | -6.375 | 40,64 | 81.28 |
12 | 3 | 36 | 0,625 | 0,39 | 1.17 |
vijftien | 3 | Vier vijf | 3.625 | 13.14 | 39.42 |
Totaal | 8 | 91 |
|
| 121,87 |
Gemiddelde (μ) = ∑(f i X i )/∑(v i )
⇒ Gemiddelde (μ) = 91/8 = 11,375
lexicografische volgordeσ = √(∑ i N F i (X i - M) 2 /N)
⇒ σ = √[(121,87)/(8)]
⇒ σ = √(15,234)
⇒ σ = 3,90
Standaardafleiding (σ) = 3,90
Oplossing:
Klas | Xi | Fi | f×Xi | Xi – μ | (Xi – μ)2 | f×(Xi- M)2 |
|---|---|---|---|---|---|---|
0-10 | 5 | 3 | vijftien | -vijftien | 225 | 675 |
10-20 | vijftien | 6 | 90 | -5 | 25 | 150 |
20-30 | 25 | 4 | 100 invoegpython | 5 | 25 | 100 |
30-40 | 35 | 2 | 70 | vijftien | 225 | 450 |
40-50 | Vier vijf | 1 | Vier vijf | 25 | 625 | 625 |
Totaal |
| 16 | 320 |
|
| 2000 |
Gemiddelde (μ) = ∑(fi xi)/∑(fi)
⇒ Gemiddelde (μ) = 320/16 = 20
σ = √(∑ i N F i (X i - M) 2 /N)
⇒ σ = √[(2000)/(16)]
⇒ σ = √(125)
⇒ σ = 11,18
Standaardafleiding (σ) = 11,18
Rekening: Methoden voor het berekenen van standaardafwijkingen in discrete reeksen
Voor een uitgebreide collectie van wiskundige formules over verschillende niveaus en concepten, blijf techcodeview.com volgen.
Controleer ook:
- Gemiddeld, mediaan, modus
- Algemene drang
Standaardafwijkingsformule Excel
- Eenvoudige berekening: gebruik de ingebouwde functies van Excel
STDEV.P>voor de gehele bevolking ofSTDEV.S>voor een monster. - Stapsgewijze handleiding: Voer uw dataset in één kolom in en typ vervolgens
=STDEV.S(A1:A10)>(vervang A1:A10 door uw gegevensbereik) in een nieuwe cel om de standaarddeviatie voor een steekproef te krijgen. - Visuele hulpmiddelen: gebruik de grafiekhulpmiddelen van Excel om de gegevensvariabiliteit naast de standaardafwijking visueel weer te geven.
Rekening: Methoden voor het berekenen van de standaardafwijking in frequentieverdelingsreeksen
Statistieken van standaarddeviatieformules
- Kernconcept: Standaardafwijking meet de hoeveelheid variatie of spreiding van een reeks waarden.
- Belangrijk inzicht: Een lage standaardafwijking geeft aan dat de waarden dicht bij het gemiddelde liggen, terwijl een hoge standaardafwijking aangeeft dat de waarden over een groter bereik verspreid zijn.
- Statistische significantie: wordt gebruikt om te bepalen of verschillen tussen groepen het gevolg zijn van toeval, vooral bij het testen van hypothesen en experimentele gegevensanalyse.
Conclusie – Standaardafwijking
De standaarddeviatie biedt waardevolle informatie over de variabiliteit of consistentie binnen een dataset. Het wordt veel gebruikt op verschillende gebieden, waaronder statistiek, financiën en wetenschap, om de distributie van gegevens te begrijpen en weloverwogen beslissingen te nemen op basis van de aanwezige mate van variabiliteit.
Veelgestelde vragen over standaardafwijkingen
Wat is standaarddeviatie in de statistiek?
Standaardafwijking definieert de volatiliteit in de waarden van de gegevens ten opzichte van de gemiddelde waarde van de gegeven dataset. Het wordt gedefinieerd als de vierkantswortel van het kwadraat van het gemiddelde van de afwijking.
Hoe standaarddeviatie berekenen?
Standaardafwijking wordt berekend met behulp van de formule,
σ =
Waarom wordt standaarddeviatie gebruikt? Standaardafwijking wordt voor verschillende doeleinden gebruikt. Enkele van de belangrijkste toepassingen zijn:
- Het wordt gebruikt voor het vinden van de volatiliteit in de waarden van de gegevens ten opzichte van de gemiddelde waarde.
- Het wordt gebruikt om het afwijkingsbereik van de gegevens te vinden.
- Het voorspelt de maximale volatiliteit in de gegeven waarde van de dataset.
Wat is het verschil tussen standaarddeviatie en variantie?
De variantie wordt berekend door het gemiddelde van de kwadratische afwijking van het gemiddelde te nemen, terwijl de standaardafwijking de vierkantswortel van de variantie is. Het andere verschil tussen hen zit in hun eenheid. Standaardafwijking wordt uitgedrukt in dezelfde eenheden als de oorspronkelijke waarden, terwijl variantie wordt uitgedrukt in eenheden2.
Werkelijke gemiddelde methode
Aangenomen gemiddelde methode Stapafwijkingsmethode Kan standaarddeviatie negatief zijn?
Nee, de standaarddeviatie kan nooit negatief zijn, aangezien we in de formule kunnen zien dat alle termen die negatief kunnen zijn, in het kwadraat zijn.
Wat is standaarddeviatie, leg uit met voorbeelden?
Standaarddeviatie is de maatstaf voor de variatie of spreiding van de gegeven waarden van de dataset.
Voorbeeld: Om het gemiddelde van 1, 2, 3 en 4 te vinden
Gemiddelde van gegevens = 13/4 = 3,25
Standaarddeviatie = √[(3,25-1)2 + (3-3,25)2 + (4-3,25)2 + (5-3,25)2]/4 = √2,06 = 1,43
Wat is de formule voor standaarddeviatie?
Standaardafwijkingsformule is,
Standaardafwijking (σ) = √[ Σ(x – μ) 2 / N]
Wanneer de standaarddeviatie 1 is?
Standaarddeviatie met 1 en gemiddelde 0 wordt standaardnormale verdeling genoemd.
Wat is de standaardafwijking van de eerste 10 natuurlijke getallen?
Standaarddeviatie van de eerste 10 natuurlijke getallen is 2,87
Wat is de standaarddeviatie van 40, 42 en 48?
De standaardafwijking van 40, 42 en 48 is 3,399
Welke standaarddeviatie vertelt u?
Standaarddeviatie is een maatstaf voor de spreiding voor de normale verdeling. Standaarddeviatie vertelt ons de spreiding van de dataset rond de gemiddelde waarde van de dataset.