Machine learning is de tak van Kunstmatige intelligentie dat zich richt op het ontwikkelen van modellen en algoritmen waarmee computers kunnen leren van gegevens en kunnen verbeteren op basis van eerdere ervaringen, zonder dat ze expliciet voor elke taak zijn geprogrammeerd. In eenvoudige bewoordingen leert ML de systemen om als mensen te denken en te begrijpen door van de gegevens te leren.
In dit artikel zullen we de verschillende verkennen types van machine learning-algoritmen die belangrijk zijn voor toekomstige eisen. Machinaal leren is over het algemeen een trainingssysteem om te leren van ervaringen uit het verleden en de prestaties in de loop van de tijd te verbeteren. Machinaal leren helpt bij het voorspellen van enorme hoeveelheden gegevens. Het helpt om snelle en nauwkeurige resultaten te leveren om winstgevende kansen te krijgen.
Soorten machinaal leren
Er zijn verschillende soorten machine learning, elk met bijzondere kenmerken en toepassingen. Enkele van de belangrijkste typen machine learning-algoritmen zijn als volgt:
10 van 100
- Begeleid machinaal leren
- Machine learning zonder toezicht
- Semi-onder toezicht machinaal leren
- Versterkend leren
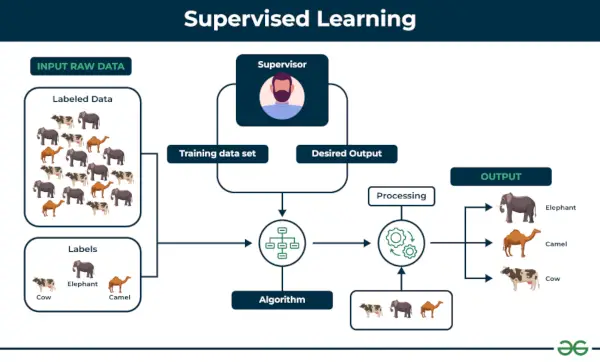
Soorten machinaal leren
1. Begeleid machinaal leren
Leren onder toezicht wordt gedefinieerd als wanneer een model wordt getraind op a Gelabelde gegevensset . Gelabelde gegevenssets hebben zowel invoer- als uitvoerparameters. In Leren onder toezicht algoritmen leren punten tussen invoer in kaart te brengen en uitvoer te corrigeren. Er zijn zowel trainings- als validatiegegevenssets gelabeld.
Leren onder toezicht
Laten we het begrijpen met behulp van een voorbeeld.
Voorbeeld: Overweeg een scenario waarin u een beeldclassificator moet bouwen om onderscheid te maken tussen katten en honden. Als je de datasets van gelabelde afbeeldingen van honden en katten aan het algoritme toevoegt, leert de machine op basis van deze gelabelde afbeeldingen te classificeren tussen een hond of een kat. Wanneer we nieuwe honden- of kattenafbeeldingen invoeren die hij nog nooit eerder heeft gezien, zal hij de geleerde algoritmen gebruiken en voorspellen of het een hond of een kat is. Dit is hoe leren onder toezicht werkt, en dit is vooral een beeldclassificatie.
Er zijn twee hoofdcategorieën van begeleid leren die hieronder worden vermeld:
- Classificatie
- Regressie
Classificatie
Classificatie houdt zich bezig met voorspellen categorisch doelvariabelen, die afzonderlijke klassen of labels vertegenwoordigen. Bijvoorbeeld het classificeren van e-mails als spam of niet, of het voorspellen of een patiënt een hoog risico op hartziekten heeft. Classificatie-algoritmen leren de invoerfuncties toe te wijzen aan een van de vooraf gedefinieerde klassen.
Hier zijn enkele classificatie-algoritmen:
- Logistieke regressie
- Ondersteuning van vectormachine
- Willekeurig bos
- Beslissingsboom
- K-dichtstbijzijnde buren (KNN)
- Naïeve Bayes
Regressie
Regressie , aan de andere kant, gaat over voorspellen continu doelvariabelen, die numerieke waarden vertegenwoordigen. Bijvoorbeeld het voorspellen van de prijs van een huis op basis van de grootte, locatie en voorzieningen, of het voorspellen van de verkoop van een product. Regressie-algoritmen leren de invoerfuncties toe te wijzen aan een continue numerieke waarde.
Hier zijn enkele regressie-algoritmen:
- Lineaire regressie
- Polynomiale regressie
- Ridge-regressie
- Lasso-regressie
- Beslissingsboom
- Willekeurig bos
Voordelen van begeleid machinaal leren
- Leren onder toezicht modellen kunnen een hoge nauwkeurigheid hebben als ze worden getraind gelabelde gegevens .
- Het besluitvormingsproces in modellen voor begeleid leren is vaak interpreteerbaar.
- Het kan vaak worden gebruikt in vooraf getrainde modellen, wat tijd en middelen bespaart bij het helemaal opnieuw ontwikkelen van nieuwe modellen.
Nadelen van begeleid machinaal leren
- Het heeft beperkingen in het kennen van patronen en kan worstelen met onzichtbare of onverwachte patronen die niet aanwezig zijn in de trainingsgegevens.
- Het kan tijdrovend en kostbaar zijn als het afhankelijk is gelabeld alleen gegevens.
- Het kan leiden tot slechte generalisaties op basis van nieuwe gegevens.
Toepassingen van begeleid leren
Begeleid leren wordt gebruikt in een breed scala aan toepassingen, waaronder:
- Beeldclassificatie : objecten, gezichten en andere kenmerken in afbeeldingen identificeren.
- Natuurlijke taalverwerking: Haal informatie uit tekst, zoals sentiment, entiteiten en relaties.
- Spraakherkenning : Gesproken taal omzetten in tekst.
- Aanbevelingssystemen : gepersonaliseerde aanbevelingen doen aan gebruikers.
- Voorspellende analyse : Voorspel resultaten, zoals verkopen, klantverloop en aandelenkoersen.
- Medische diagnose : Detecteer ziekten en andere medische aandoeningen.
- Fraude detectie : Identificeer frauduleuze transacties.
- Autonome voertuigen : Herkennen en reageren op objecten in de omgeving.
- Detectie van e-mailspam : Classificeer e-mails als spam of geen spam.
- Kwaliteitscontrole in de productie : Inspecteer producten op gebreken.
- Kredietscore : Beoordeel het risico dat een kredietnemer in gebreke blijft met een lening.
- Gamen : Herken karakters, analyseer het gedrag van spelers en creëer NPC's.
- Klantenservice : Automatiseer klantenondersteuningstaken.
- Weersvoorspelling : voorspellingen doen voor temperatuur, neerslag en andere meteorologische parameters.
- Sportanalyse : Analyseer de prestaties van spelers, maak spelvoorspellingen en optimaliseer strategieën.
2. Machine learning zonder toezicht
Ongecontroleerd leren Unsupervised learning is een soort machine learning-techniek waarbij een algoritme patronen en relaties ontdekt met behulp van ongelabelde gegevens. In tegenstelling tot leren onder toezicht houdt het leren zonder toezicht niet in dat het algoritme wordt voorzien van gelabelde doelresultaten. Het primaire doel van onbewaakt leren is vaak het ontdekken van verborgen patronen, overeenkomsten of clusters binnen de gegevens, die vervolgens voor verschillende doeleinden kunnen worden gebruikt, zoals gegevensverkenning, visualisatie, dimensionaliteitsreductie en meer.
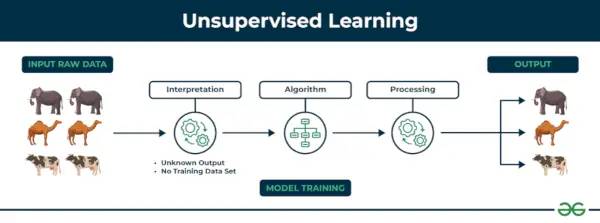
Ongecontroleerd leren
Laten we het begrijpen met behulp van een voorbeeld.
Voorbeeld: Stel dat u een dataset heeft die informatie bevat over de aankopen die u in de winkel heeft gedaan. Door clustering kan het algoritme hetzelfde koopgedrag onder u en andere klanten groeperen, waardoor potentiële klanten zonder vooraf gedefinieerde labels zichtbaar worden. Dit soort informatie kan bedrijven helpen doelgroepen te werven en uitschieters te identificeren.
Er zijn twee hoofdcategorieën van onbegeleid leren die hieronder worden vermeld:
- Clustering
- Vereniging
Clustering
Clustering is het proces waarbij datapunten in clusters worden gegroepeerd op basis van hun gelijkenis. Deze techniek is handig voor het identificeren van patronen en relaties in gegevens zonder dat er gelabelde voorbeelden nodig zijn.
Hier zijn enkele clusteralgoritmen:
- K-Means Clustering-algoritme
- Mean-shift-algoritme
- DBSCAN-algoritme
- Hoofdcomponentenanalyse
- Onafhankelijke componentanalyse
Vereniging
Associatieregel leren ing is een techniek om relaties tussen items in een dataset te ontdekken. Het identificeert regels die aangeven dat de aanwezigheid van één item de aanwezigheid van een ander item met een specifieke waarschijnlijkheid impliceert.
Hier zijn enkele algoritmen voor het leren van associatieregels:
- Apriori-algoritme
- Gloed
- FP-groei-algoritme
Voordelen van machinaal leren zonder toezicht
- Het helpt om verborgen patronen en verschillende relaties tussen de gegevens te ontdekken.
- Gebruikt voor taken zoals klantsegmentatie, detectie van afwijkingen, En gegevensverkenning .
- Er zijn geen gelabelde gegevens nodig en het vermindert de moeite van het labelen van gegevens.
Nadelen van machinaal leren zonder toezicht
- Zonder labels te gebruiken kan het moeilijk zijn om de kwaliteit van de output van het model te voorspellen.
- Clusterinterpreteerbaarheid is mogelijk niet duidelijk en heeft mogelijk geen betekenisvolle interpretaties.
- Het heeft technieken zoals automatische encoders En dimensionaliteitsreductie die kunnen worden gebruikt om betekenisvolle kenmerken uit ruwe gegevens te halen.
Toepassingen van onbewaakt leren
Hier zijn enkele veelvoorkomende toepassingen van leren zonder toezicht:
Java converteert tekenreeks naar geheel getal
- Clustering : Groepeer vergelijkbare gegevenspunten in clusters.
- Onregelmatigheidsdetectie : Identificeer uitschieters of afwijkingen in gegevens.
- Dimensionaliteitsreductie : Reduceer de dimensionaliteit van gegevens terwijl de essentiële informatie behouden blijft.
- Aanbevelingssystemen : producten, films of inhoud voorstellen aan gebruikers op basis van hun historische gedrag of voorkeuren.
- Onderwerp modellering : Ontdek latente onderwerpen binnen een verzameling documenten.
- Schatting van de dichtheid : Schat de waarschijnlijkheidsdichtheidsfunctie van gegevens.
- Beeld- en videocompressie : verminder de hoeveelheid opslagruimte die nodig is voor multimedia-inhoud.
- Voorverwerking van gegevens : Hulp bij taken voor het voorbewerken van gegevens, zoals het opschonen van gegevens, het imputeren van ontbrekende waarden en het schalen van gegevens.
- Analyse van het marktmandje : Ontdek associaties tussen producten.
- Genomische data-analyse : Identificeer patronen of groepeer genen met vergelijkbare expressieprofielen.
- Segmentatie van afbeeldingen : segmenteer afbeeldingen in betekenisvolle regio's.
- Communitydetectie in sociale netwerken : Identificeer gemeenschappen of groepen individuen met vergelijkbare interesses of connecties.
- Analyse van klantgedrag : Ontdek patronen en inzichten voor betere marketing- en productaanbevelingen.
- Inhoudelijke aanbeveling : Classificeer en tag inhoud om het gemakkelijker te maken vergelijkbare items aan te bevelen aan gebruikers.
- Verkennende data-analyse (EDA) : Verken gegevens en verkrijg inzichten voordat u specifieke taken definieert.
3. Semi-begeleid leren
Semi-begeleid leren is een machine learning-algoritme dat werkt tussen de onder toezicht en zonder toezicht leren zodat het beide gebruikt gelabeld en ongelabeld gegevens. Het is vooral handig wanneer het verkrijgen van gelabelde gegevens kostbaar, tijdrovend of arbeidsintensief is. Deze aanpak is handig wanneer de dataset duur en tijdrovend is. Er wordt gekozen voor semi-gesuperviseerd leren wanneer gelabelde data vaardigheden en relevante middelen vereisen om te trainen of ervan te leren.
We gebruiken deze technieken als we te maken hebben met gegevens die een klein beetje gelabeld zijn, terwijl het overige grote deel ongelabeld is. We kunnen de niet-gecontroleerde technieken gebruiken om labels te voorspellen en deze labels vervolgens aan begeleide technieken toe te voegen. Deze techniek is vooral toepasbaar in het geval van beeldgegevenssets waarbij doorgaans niet alle afbeeldingen zijn gelabeld.
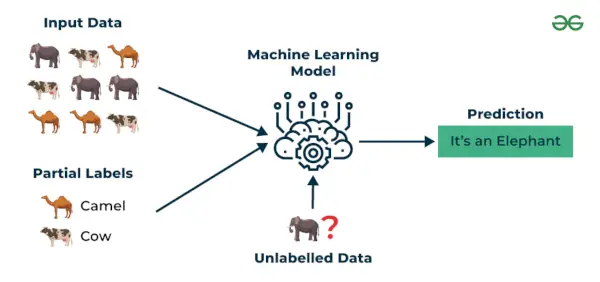
Semi-begeleid leren
Laten we het begrijpen met behulp van een voorbeeld.
Voorbeeld : Bedenk dat we een taalvertaalmodel aan het bouwen zijn, waarbij het hebben van gelabelde vertalingen voor elk zinspaar veel middelen kan vergen. Hierdoor kunnen de modellen leren van gelabelde en ongelabelde zinsparen, waardoor ze nauwkeuriger worden. Deze techniek heeft geleid tot aanzienlijke verbeteringen in de kwaliteit van machinevertaaldiensten.
Soorten semi-begeleide leermethoden
Er zijn een aantal verschillende semi-begeleide leermethoden, elk met hun eigen kenmerken. Enkele van de meest voorkomende zijn:
- Op grafieken gebaseerd semi-begeleid leren: Deze aanpak maakt gebruik van een grafiek om de relaties tussen de gegevenspunten weer te geven. De grafiek wordt vervolgens gebruikt om labels door te geven van de gelabelde datapunten naar de ongelabelde datapunten.
- Labelvoortplanting: Deze aanpak propageert labels iteratief van de gelabelde datapunten naar de niet-gelabelde datapunten, op basis van de overeenkomsten tussen de datapunten.
- Co-training: Deze aanpak traint twee verschillende machine learning-modellen op verschillende subsets van de ongelabelde gegevens. De twee modellen worden vervolgens gebruikt om elkaars voorspellingen te labelen.
- Zelfstudie: Deze aanpak traint een machine learning-model op de gelabelde gegevens en gebruikt het model vervolgens om labels voor de niet-gelabelde gegevens te voorspellen. Het model wordt vervolgens opnieuw getraind op de gelabelde gegevens en de voorspelde labels voor de niet-gelabelde gegevens.
- Generatieve vijandige netwerken (GAN's) : GAN's zijn een soort deep learning-algoritmen die kunnen worden gebruikt om synthetische gegevens te genereren. GAN's kunnen worden gebruikt om ongelabelde gegevens te genereren voor semi-gecontroleerd leren door twee neurale netwerken, een generator en een discriminator, te trainen.
Voordelen van machinaal leren met semi-supervisie
- Het leidt tot een betere generalisatie in vergelijking met leren onder toezicht, omdat er zowel gelabelde als ongelabelde gegevens nodig zijn.
- Kan worden toegepast op een breed scala aan gegevens.
Nadelen van semi-gecontroleerd machinaal leren
- Semi-bewaakt methoden kunnen complexer zijn om te implementeren in vergelijking met andere benaderingen.
- Het vergt nog wel wat gelabelde gegevens die misschien niet altijd beschikbaar of gemakkelijk te verkrijgen zijn.
- De niet-gelabelde gegevens kunnen dienovereenkomstig de modelprestaties beïnvloeden.
Toepassingen van semi-begeleid leren
Hier zijn enkele veelvoorkomende toepassingen van semi-onder toezicht leren:
- Beeldclassificatie en objectherkenning : Verbeter de nauwkeurigheid van modellen door een kleine set gelabelde afbeeldingen te combineren met een grotere set ongelabelde afbeeldingen.
- Natuurlijke taalverwerking (NLP) : Verbeter de prestaties van taalmodellen en classificaties door een kleine set gelabelde tekstgegevens te combineren met een enorme hoeveelheid ongelabelde tekst.
- Spraakherkenning: Verbeter de nauwkeurigheid van spraakherkenning door gebruik te maken van een beperkte hoeveelheid getranscribeerde spraakgegevens en een uitgebreidere set ongelabelde audio.
- Aanbevelingssystemen : Verbeter de nauwkeurigheid van gepersonaliseerde aanbevelingen door een beperkte reeks interacties tussen gebruikers en items (gelabelde gegevens) aan te vullen met een schat aan niet-gelabelde gegevens over gebruikersgedrag.
- Gezondheidszorg en medische beeldvorming : Verbeter de analyse van medische beelden door gebruik te maken van een kleine set gelabelde medische beelden naast een grotere set ongelabelde beelden.
4. Versterking van machinaal leren
Versterking van machinaal leren algoritme is een leermethode die interageert met de omgeving door acties te ondernemen en fouten te ontdekken. Trial, error en vertraging zijn de meest relevante kenmerken van versterkend leren. Bij deze techniek blijft het model zijn prestaties verbeteren met behulp van beloningsfeedback om het gedrag of patroon te leren. Deze algoritmen zijn specifiek voor een bepaald probleem, b.v. Google Zelfrijdende auto, AlphaGo waarbij een bot concurreert met mensen en zelfs zichzelf om steeds betere prestaties te krijgen in Go Game. Elke keer dat we gegevens invoeren, leren ze en voegen ze de gegevens toe aan hun kennis, namelijk trainingsgegevens. Dus hoe meer hij leert, hoe beter hij wordt opgeleid en dus ervaren.
Hier zijn enkele van de meest voorkomende algoritmen voor het leren van versterking:
- Q-leren: Q-learning is een modelvrij RL-algoritme dat een Q-functie leert, die toestanden aan acties toewijst. De Q-functie schat de verwachte beloning voor het ondernemen van een bepaalde actie in een bepaalde toestand.
- SARSA (staatsactie-beloning-staatsactie): SARSA is een ander modelvrij RL-algoritme dat een Q-functie leert. In tegenstelling tot Q-learning werkt SARSA echter de Q-functie bij voor de actie die daadwerkelijk is ondernomen, in plaats van voor de optimale actie.
- Diep Q-leren : Deep Q-learning is een combinatie van Q-learning en deep learning. Deep Q-learning maakt gebruik van een neuraal netwerk om de Q-functie weer te geven, waardoor het complexe relaties tussen toestanden en acties kan leren.
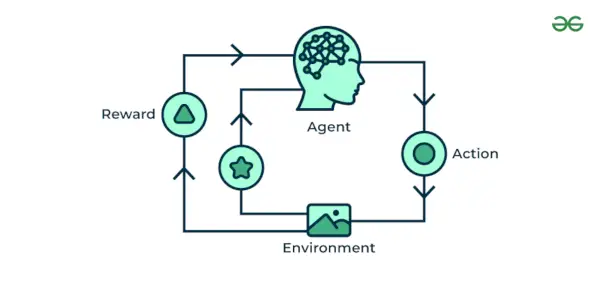
Versterking van machinaal leren
Laten we het begrijpen met behulp van voorbeelden.
Voorbeeld: Bedenk dat je een training volgt AI agent om een spel zoals schaken te spelen. De agent onderzoekt verschillende bewegingen en ontvangt positieve of negatieve feedback op basis van de uitkomst. Reinforcement Learning vindt ook toepassingen waarin ze taken leren uitvoeren door interactie met hun omgeving.
Soorten versterkingsmachine learning
Er zijn twee hoofdtypen van versterkend leren:
Positieve bekrachtiging
- Beloont de agent voor het ondernemen van een gewenste actie.
- Moedigt de agent aan om het gedrag te herhalen.
- Voorbeelden: Een hond iets lekkers geven omdat hij zit, een punt in een spel opleveren voor een juist antwoord.
Negatieve bekrachtiging
- Verwijdert een ongewenste stimulus om gewenst gedrag aan te moedigen.
- Ontmoedigt de agent om het gedrag te herhalen.
- Voorbeelden: een luide zoemer uitschakelen wanneer een hendel wordt ingedrukt, een straf vermijden door een taak te voltooien.
Voordelen van machinaal leren door versterking
- Het beschikt over autonome besluitvorming die zeer geschikt is voor taken en die kan leren een reeks beslissingen te nemen, zoals robotica en het spelen van games.
- Deze techniek heeft de voorkeur om resultaten op de lange termijn te bereiken die zeer moeilijk te bereiken zijn.
- Het wordt gebruikt om complexe problemen op te lossen die niet met conventionele technieken kunnen worden opgelost.
Nadelen van machinaal leren door versterking
- Trainingsversterking Leermiddelen kunnen rekentechnisch duur en tijdrovend zijn.
- Versterkend leren heeft niet de voorkeur boven het oplossen van eenvoudige problemen.
- Er zijn veel gegevens en berekeningen voor nodig, wat het onpraktisch en duur maakt.
Toepassingen van machinaal leren door versterking
Hier zijn enkele toepassingen van versterkend leren:
- Spel spelen : RL kan agenten leren games te spelen, zelfs complexe.
- Robotica : RL kan robots leren taken autonoom uit te voeren.
- Autonome voertuigen : RL kan zelfrijdende auto's helpen navigeren en beslissingen nemen.
- Aanbevelingssystemen : RL kan aanbevelingsalgoritmen verbeteren door gebruikersvoorkeuren te leren.
- Gezondheidszorg : RL kan worden gebruikt om behandelplannen en de ontdekking van geneesmiddelen te optimaliseren.
- Natuurlijke taalverwerking (NLP) : RL kan worden gebruikt in dialoogsystemen en chatbots.
- Financiën en handel : RL kan worden gebruikt voor algoritmische handel.
- Supply Chain- en voorraadbeheer : RL kan worden gebruikt om supply chain-operaties te optimaliseren.
- Energiebeheer : RL kan worden gebruikt om het energieverbruik te optimaliseren.
- AI-spellen : RL kan worden gebruikt om intelligentere en adaptievere NPC's in videogames te creëren.
- Adaptieve persoonlijke assistenten : RL kan worden gebruikt om persoonlijke assistenten te verbeteren.
- Virtuele Realiteit (VR) en Augmented Reality (AR): RL kan worden gebruikt om meeslepende en interactieve ervaringen te creëren.
- Industriële controle : RL kan worden gebruikt om industriële processen te optimaliseren.
- Onderwijs : RL kan worden gebruikt om adaptieve leersystemen te creëren.
- landbouw : RL kan worden gebruikt om landbouwactiviteiten te optimaliseren.
Moet controleren, ons gedetailleerde artikel over : Machine learning-algoritmen
touwtje eraan
Conclusie
Concluderend dient elk type machine learning zijn eigen doel en draagt het bij aan de algemene rol in de ontwikkeling van verbeterde mogelijkheden voor gegevensvoorspelling, en heeft het het potentieel om verschillende industrieën te veranderen, zoals Datawetenschap . Het helpt bij het omgaan met enorme gegevensproductie en het beheer van de datasets.
Soorten machinaal leren – Veelgestelde vragen
1. Wat zijn de uitdagingen bij begeleid leren?
Enkele van de uitdagingen bij begeleid leren zijn voornamelijk het aanpakken van onevenwichtigheden in klassen, gelabelde gegevens van hoge kwaliteit en het vermijden van overfitting waarbij modellen slecht presteren op basis van realtime gegevens.
2. Waar kunnen we begeleid leren toepassen?
Begeleid leren wordt vaak gebruikt voor taken zoals het analyseren van spam-e-mails, beeldherkenning en sentimentanalyse.
3. Hoe ziet de toekomst van machine learning eruit?
Machine learning als toekomstperspectief kan werken op gebieden als weer- of klimaatanalyse, gezondheidszorgsystemen en autonome modellering.
4. Wat zijn de verschillende soorten machinaal leren?
Er zijn drie hoofdtypen machine learning:
- Leren onder toezicht
- Ongecontroleerd leren
- Versterkend leren
5. Wat zijn de meest voorkomende machine learning-algoritmen?
Enkele van de meest voorkomende machine learning-algoritmen zijn:
- Lineaire regressie
- Logistieke regressie
- Ondersteuning van vectormachines (SVM's)
- K-dichtstbijzijnde buren (KNN)
- Beslissingsbomen
- Willekeurige bossen
- Kunstmatige neurale netwerken