Een belangrijk aspect van Machinaal leren is modelevaluatie. U hebt een mechanisme nodig om uw model te evalueren. Dit is waar deze prestatiestatistieken in beeld komen: ze geven ons een idee van hoe goed een model is. Als u bekend bent met enkele basisprincipes van Machinaal leren dan ben je vast een aantal van deze meetgegevens tegengekomen, zoals nauwkeurigheid, precisie, herinnering, auc-roc, enz., die over het algemeen worden gebruikt voor classificatietaken. In dit artikel zullen we een dergelijke maatstaf diepgaand onderzoeken, namelijk de AUC-ROC-curve.
Inhoudsopgave
- Wat is de AUC-ROC-curve?
- Sleutelbegrippen die worden gebruikt in de AUC- en ROC-curve
- Relatie tussen gevoeligheid, specificiteit, FPR en drempelwaarde.
- Hoe werkt AUC-ROC?
- Wanneer moeten we de AUC-ROC-evaluatiemetriek gebruiken?
- Speculeren over de prestaties van het model
- Inzicht in de AUC-ROC-curve
- Implementatie met behulp van twee verschillende modellen
- Hoe ROC-AUC gebruiken voor een model met meerdere klassen?
- Veelgestelde vragen over AUC ROC Curve in Machine Learning
Wat is de AUC-ROC-curve?
De AUC-ROC-curve, of Area Under the Receiver Operating Characteristic-curve, is een grafische weergave van de prestaties van een binair classificatiemodel bij verschillende classificatiedrempels. Het wordt vaak gebruikt bij machinaal leren om het vermogen van een model te beoordelen om onderscheid te maken tussen twee klassen, doorgaans de positieve klasse (bijvoorbeeld de aanwezigheid van een ziekte) en de negatieve klasse (bijvoorbeeld de afwezigheid van een ziekte).
Laten we eerst de betekenis van de twee termen begrijpen ROC En AUC .
- ROC : Bedieningskenmerken van de ontvanger
- AUC : Gebied onder curve
Ontvanger bedrijfskarakteristieken (ROC) curve
ROC staat voor Receiver Operating Characteristics, en de ROC-curve is de grafische weergave van de effectiviteit van het binaire classificatiemodel. Het geeft het werkelijk positieve percentage (TPR) weer versus het fout-positieve percentage (FPR) bij verschillende classificatiedrempels.
Gebied onder curve (AUC)-curve:
AUC staat voor Area Under the Curve, en de AUC-curve vertegenwoordigt het gebied onder de ROC-curve. Het meet de algehele prestaties van het binaire classificatiemodel. Omdat zowel TPR als FPR tussen 0 en 1 liggen, zal het gebied dus altijd tussen 0 en 1 liggen, en een grotere waarde van AUC duidt op betere modelprestaties. Ons belangrijkste doel is om dit gebied te maximaliseren om de hoogste TPR en de laagste FPR te hebben bij de gegeven drempel. De AUC meet de waarschijnlijkheid dat het model een willekeurig gekozen positief exemplaar een hogere voorspelde waarschijnlijkheid zal toekennen vergeleken met een willekeurig gekozen negatief exemplaar.
Het vertegenwoordigt de waarschijnlijkheid waarmee ons model onderscheid kan maken tussen de twee klassen die aanwezig zijn in ons doel.
ROC-AUC Classificatie Evaluatie Metrisch
Sleutelbegrippen die worden gebruikt in de AUC- en ROC-curve
1. TPR en FPR
Dit is de meest voorkomende definitie die u tegenkomt als u AUC-ROC gebruikt. Kortom, de ROC-curve is een grafiek die de prestaties van een classificatiemodel bij alle mogelijke drempels weergeeft (drempel is een bepaalde waarde waarboven u zegt dat een punt tot een bepaalde klasse behoort). De curve wordt uitgezet tussen twee parameters
- TPR – Echt positief tarief
- FPR – Vals-positief percentage
Voordat we het begrijpen, laten TPR en FPR ons snel kijken naar de verwarringsmatrix .
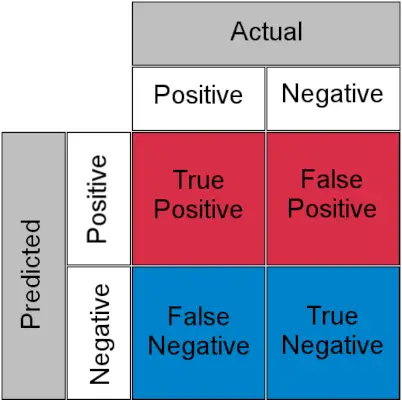
Verwarringsmatrix voor een classificatietaak
- Echt positief : Werkelijk positief en voorspeld als positief
- Echt negatief : Werkelijk negatief en voorspeld als negatief
- Vals positief (type I-fout) : Werkelijk negatief, maar voorspeld als positief
- Vals negatief (type II-fout) : Werkelijk positief, maar voorspeld als negatief
In eenvoudige bewoordingen kun je False Positive a noemen vals alarm en fout-negatief a missen . Laten we nu eens kijken naar wat TPR en FPR zijn.
2. Gevoeligheid / Echt positief percentage / Terugroepen
Kortom, TPR/Recall/Sensitivity is de verhouding tussen positieve voorbeelden die correct zijn geïdentificeerd. Het vertegenwoordigt het vermogen van het model om positieve gevallen correct te identificeren en wordt als volgt berekend:

Gevoeligheid/Herinnering/TPR meet het aandeel daadwerkelijke positieve gevallen dat door het model correct als positief wordt geïdentificeerd.
3. Vals-positief percentage
FPR is de verhouding van negatieve voorbeelden die onjuist zijn geclassificeerd.

4. Specificiteit
Specificiteit meet het aandeel daadwerkelijke negatieve gevallen dat door het model correct als negatief wordt geïdentificeerd. Het vertegenwoordigt het vermogen van het model om negatieve gevallen correct te identificeren

En zoals eerder gezegd is ROC niets anders dan de grafiek tussen TPR en FPR over alle mogelijke drempels heen, en AUC is het gehele gebied onder deze ROC-curve.
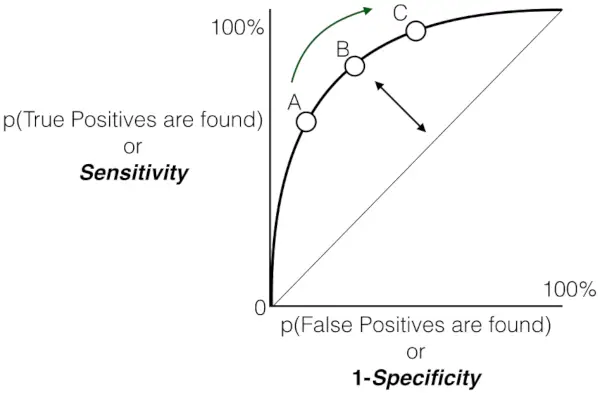
Gevoeligheid versus False Positive Rate-grafiek
Relatie tussen gevoeligheid, specificiteit, FPR en drempelwaarde .
Gevoeligheid en specificiteit:
- Omgekeerde relatie: Gevoeligheid en specificiteit hebben een omgekeerde relatie. Wanneer het ene toeneemt, heeft het andere de neiging te dalen. Dit weerspiegelt de inherente wisselwerking tussen werkelijk positieve en werkelijk negatieve rentetarieven.
- Afstemmen via drempel: Door de drempelwaarde aan te passen, kunnen we de balans tussen gevoeligheid en specificiteit controleren. Lagere drempels leiden tot een hogere gevoeligheid (meer echte positieven) ten koste van de specificiteit (meer valse positieven). Omgekeerd verhoogt het verhogen van de drempel de specificiteit (minder valse positieven), maar gaat dit ten koste van de gevoeligheid (meer valse negatieven).
Drempel en fout-positief percentage (FPR):
- FPR en specificiteitsverbinding: False Positive Rate (FPR) is eenvoudigweg het complement van specificiteit (FPR = 1 – specificiteit). Dit duidt op de directe relatie tussen beide: een hogere specificiteit vertaalt zich in een lagere FPR, en omgekeerd.
- FPR-wijzigingen met TPR: Op dezelfde manier zijn, zoals u hebt opgemerkt, de True Positive Rate (TPR) en de FPR ook met elkaar verbonden. Een toename van de TPR (meer echte positieven) leidt doorgaans tot een stijging van de FPR (meer valse positieven). Omgekeerd resulteert een daling van de TPR (minder echte positieven) in een daling van de FPR (minder valse positieven)
Hoe werkt AUC-ROC?
We hebben naar de geometrische interpretatie gekeken, maar ik denk dat dit nog steeds niet voldoende is om de intuïtie te ontwikkelen achter wat 0,75 AUC eigenlijk betekent. Laten we nu naar AUC-ROC kijken vanuit een probabilistisch gezichtspunt. Laten we eerst praten over wat AUC doet en later zullen we ons begrip hierover uitbreiden
AUC meet hoe goed een model onderscheid kan maken tussen klassen.
Een AUC van 0,75 zou feitelijk betekenen dat we, laten we zeggen dat we twee datapunten nemen die tot afzonderlijke klassen behoren, dan is er een kans van 75% dat het model ze kan scheiden of op de juiste manier kan rangschikken, dat wil zeggen dat het positieve punt een hogere voorspellingskans heeft dan het negatieve. klas. (aangenomen dat een hogere voorspellingswaarschijnlijkheid betekent dat het punt idealiter tot de positieve klasse zou behoren). Hier is een klein voorbeeld om het allemaal duidelijker te maken.
Inhoudsopgave | Klas | Waarschijnlijkheid |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Hier hebben we 6 punten waarbij P1, P2 en P5 tot klasse 1 behoren en P3, P4 en P6 tot klasse 0 en we corresponderen met de voorspelde waarschijnlijkheden in de kolom Waarschijnlijkheid, zoals we al zeiden als we twee punten nemen die tot afzonderlijke punten behoren. klassen, wat is dan de kans dat het model ze correct rangschikt?
We nemen alle mogelijke paren zodat het ene punt tot klasse 1 behoort en het andere tot klasse 0. We hebben in totaal 9 van dergelijke paren. Hieronder staan al deze 9 mogelijke paren.
Paar | is juist |
|---|---|
(P1,P3) | Ja |
(P1,P4) katrina kaif | Ja |
(P1,P6) | Ja |
(P2,P3) | Ja |
(P2,P4) | Ja |
(P2,P6) | Ja |
(P3,P5) | Nee |
(P4,P5) | Nee |
(P5,P6) | Ja |
Hier geeft de kolom Correct aan of het genoemde paar correct gerangschikt is op basis van de voorspelde waarschijnlijkheid, dat wil zeggen klasse 1-punt heeft een hogere waarschijnlijkheid dan klasse 0-punt, in 7 van deze 9 mogelijke paren is klasse 1 hoger gerangschikt dan klasse 0, of we kunnen zeggen dat er een kans van 77% is dat als je een paar punten kiest die tot afzonderlijke klassen behoren, het model ze correct zou kunnen onderscheiden. Nu denk ik dat je misschien een beetje intuïtie hebt achter dit AUC-nummer. Om eventuele verdere twijfels op te helderen, laten we het valideren met behulp van Scikit leert de AUC-ROC-implementatie.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Uitgang:
AUC for our sample data is 0.778>
Wanneer moeten we de AUC-ROC-evaluatiemetriek gebruiken?
Er zijn een aantal gebieden waar het gebruik van ROC-AUC mogelijk niet ideaal is. In gevallen waarin de dataset zeer onevenwichtig is, de ROC-curve kan een te optimistische beoordeling geven van de prestaties van het model . Deze optimisme-bias ontstaat omdat de false positive rate (FPR) van de ROC-curve erg klein kan worden als het aantal feitelijke negatieven groot is.
Kijkend naar de FPR-formule,

We observeren ,
- De Negatieve klasse is in de meerderheid, de noemer van FPR wordt gedomineerd door True Negatives, waardoor FPR minder gevoelig wordt voor veranderingen in voorspellingen gerelateerd aan de minderheidsklasse (positieve klasse).
- ROC-curven kunnen geschikt zijn als de kosten van valse positieven en valse negatieven in evenwicht zijn en de dataset niet zwaar uit balans is.
In dat geval Precisie-herinneringscurven kunnen worden gebruikt die een alternatieve evaluatiemetriek bieden die geschikter is voor onevenwichtige datasets, waarbij de nadruk ligt op de prestaties van de classificator met betrekking tot de positieve (minderheids)klasse.
Speculeren over de prestaties van het model
- Een hoge AUC (dichtbij 1) duidt op een uitstekend onderscheidend vermogen. Dit betekent dat het model effectief onderscheid kan maken tussen de twee klassen, en dat de voorspellingen betrouwbaar zijn.
- Een lage AUC (dicht bij 0) duidt op slechte prestaties. In dit geval heeft het model moeite om onderscheid te maken tussen de positieve en negatieve klassen, en zijn zijn voorspellingen mogelijk niet betrouwbaar.
- Een AUC van ongeveer 0,5 impliceert dat het model in wezen willekeurige gissingen maakt. Het toont geen mogelijkheid om de klassen te scheiden, wat aangeeft dat het model geen betekenisvolle patronen uit de gegevens leert.
Inzicht in de AUC-ROC-curve
In een ROC-curve vertegenwoordigt de x-as doorgaans de False Positive Rate (FPR), en de y-as vertegenwoordigt de True Positive Rate (TPR), ook bekend als Gevoeligheid of Recall. Een hogere waarde op de x-as (naar rechts) op de ROC-curve duidt dus op een hoger percentage vals-positieven, en een hogere waarde op de y-as (naar boven) duidt op een hoger percentage waar-positief. De ROC-curve is een grafische weergave. weergave van de afweging tussen echt positief percentage en vals positief percentage bij verschillende drempels. Het toont de prestaties van een classificatiemodel bij verschillende classificatiedrempels. De AUC (Area Under the Curve) is een samenvattende maatstaf voor de prestaties van de ROC-curve. De keuze van de drempel hangt af van de specifieke vereisten van het probleem dat u probeert op te lossen en de afweging tussen valse positieven en valse negatieven. acceptabel in jouw context.
- Als u prioriteit wilt geven aan het terugdringen van het aantal valse positieven (waardoor de kans wordt geminimaliseerd dat iets als positief wordt bestempeld terwijl dit niet het geval is), kunt u een drempel kiezen die resulteert in een lager percentage valse positieven.
- Als u prioriteit wilt geven aan het verhogen van de echte positieven (zoveel mogelijk daadwerkelijke positieven vastleggen), kunt u een drempel kiezen die resulteert in een hoger percentage werkelijk positieven.
Laten we een voorbeeld bekijken om te illustreren hoe ROC-curven voor verschillende worden gegenereerd drempels en hoe een bepaalde drempel overeenkomt met een verwarringsmatrix. Stel dat we een binair classificatieprobleem met een model dat voorspelt of een e-mail spam (positief) of geen spam (negatief) is.
Laten we de hypothetische gegevens bekijken,
Ware labels: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Voorspelde kansen: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Geval 1: Drempel = 0,5
Echte etiketten | Voorspelde kansen | Voorspelde labels |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Verwarringsmatrix gebaseerd op bovenstaande voorspellingen
| Voorspelling = 0 | Voorspelling = 1 |
|---|---|---|
Werkelijk = 0 | TP=4 | FN=1 |
Werkelijk = 1 | FP=0 | TN=5 |
Overeenkomstig,
- Echt positief percentage (TPR) :
Het percentage feitelijke positieven dat correct is geïdentificeerd door de classificator is

- Vals-positief percentage (FPR) :
Het percentage daadwerkelijke negatieven dat ten onrechte als positief is geclassificeerd



Dus bij de drempel van 0,5:
- Echt positief percentage (gevoeligheid): 0,8
- Vals-positief percentage: 0
De interpretatie is dat het model bij deze drempelwaarde 80% van de feitelijke positieven (TPR) correct identificeert, maar 0% van de werkelijke negatieven ten onrechte als positief (FPR) classificeert.
Dienovereenkomstig krijgen we voor verschillende drempels:
Geval 2: Drempel = 0,7
Echte etiketten | Voorspelde kansen | Voorspelde labels |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Verwarringsmatrix gebaseerd op bovenstaande voorspellingen
| Voorspelling = 0 | Voorspelling = 1 |
|---|---|---|
Werkelijk = 0 | TP=5 | FN=0 |
Werkelijk = 1 | FP=2 | TN=3 |
Overeenkomstig,
- Echt positief percentage (TPR) :
Het percentage feitelijke positieven dat correct is geïdentificeerd door de classificator is

- Vals-positief percentage (FPR) :
Het percentage daadwerkelijke negatieven dat ten onrechte als positief is geclassificeerd



Geval 3: Drempel = 0,4
Echte etiketten | Voorspelde kansen | Voorspelde labels |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Verwarringsmatrix gebaseerd op bovenstaande voorspellingen
| Voorspelling = 0 | Voorspelling = 1 |
|---|---|---|
Werkelijk = 0 | TP=4 | FN=1 |
Werkelijk = 1 | FP=0 | TN=5 |
Overeenkomstig,
- Echt positief percentage (TPR) :
Het percentage feitelijke positieven dat correct is geïdentificeerd door de classificator is
- Vals-positief percentage (FPR) :
Het percentage daadwerkelijke negatieven dat ten onrechte als positief is geclassificeerd
Geval 4: Drempel = 0,2
Echte etiketten | Voorspelde kansen | Voorspelde labels |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Verwarringsmatrix gebaseerd op bovenstaande voorspellingen
| Voorspelling = 0 | Voorspelling = 1 |
|---|---|---|
Werkelijk = 0 | TP=2 | FN=3 |
Werkelijk = 1 | FP=0 | TN=5 |
Overeenkomstig,
- Echt positief percentage (TPR) :
Het percentage feitelijke positieven dat correct is geïdentificeerd door de classificator is

- Vals-positief percentage (FPR) :
Het percentage daadwerkelijke negatieven dat ten onrechte als positief is geclassificeerd

Geval 5: Drempel = 0,85
Echte etiketten | Voorspelde kansen | Voorspelde labels |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Verwarringsmatrix gebaseerd op bovenstaande voorspellingen
| Voorspelling = 0 | Voorspelling = 1 |
|---|---|---|
Werkelijk = 0 | TP=5 | FN=0 |
Werkelijk = 1 | FP=4 | TN=1 |
Overeenkomstig,
- Echt positief percentage (TPR) :
Het percentage feitelijke positieven dat correct is geïdentificeerd door de classificator is
- Vals-positief percentage (FPR) :
Het percentage daadwerkelijke negatieven dat ten onrechte als positief is geclassificeerd


Op basis van het bovenstaande resultaat zullen we de ROC-curve uitzetten
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Uitgang:
Uit de grafiek blijkt dat:
- De grijze stippellijn geeft het worstcasescenario weer, waarbij de voorspellingen van het model, d.w.z. TPR en FPR, hetzelfde zijn. Deze diagonale lijn wordt beschouwd als het worstcasescenario, wat wijst op een gelijke waarschijnlijkheid van valse positieven en valse negatieven.
- Naarmate punten afwijken van de willekeurige goklijn naar de linkerbovenhoek, verbeteren de prestaties van het model.
- De Area Under the Curve (AUC) is een kwantitatieve maatstaf voor het onderscheidend vermogen van het model. Een hogere AUC-waarde, dichter bij 1,0, duidt op superieure prestaties. De best mogelijke AUC-waarde is 1,0, wat overeenkomt met een model dat 100% gevoeligheid en 100% specificiteit bereikt.
In totaal dient de Receiver Operating Characteristic (ROC)-curve als een grafische weergave van de afweging tussen de True Positive Rate (gevoeligheid) en de False Positive Rate van een binair classificatiemodel bij verschillende beslissingsdrempels. Terwijl de curve sierlijk stijgt naar de linkerbovenhoek, duidt dit op het lovenswaardige vermogen van het model om onderscheid te maken tussen positieve en negatieve gevallen over een reeks vertrouwensdrempels. Dit opwaartse traject duidt op verbeterde prestaties, waarbij een hogere gevoeligheid wordt bereikt terwijl het aantal valse positieven wordt geminimaliseerd. De geannoteerde drempels, aangeduid als A, B, C, D en E, bieden waardevolle inzichten in het dynamische gedrag van het model op verschillende betrouwbaarheidsniveaus.
Implementatie met behulp van twee verschillende modellen
Bibliotheken installeren
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Om de Willekeurig bos En Logistieke regressie modellen en om hun ROC-curven met AUC-scores te presenteren, creëert het algoritme kunstmatige binaire classificatiegegevens.
Gegevens genereren en gegevens splitsen
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Met behulp van een 80-20 split ratio creëert het algoritme kunstmatige binaire classificatiegegevens met 20 kenmerken, verdeelt deze in trainings- en testsets en wijst een willekeurig zaad toe om reproduceerbaarheid te garanderen.
Trainen van de verschillende modellen
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Met behulp van een vast willekeurig zaad om herhaalbaarheid te garanderen, initialiseert en traint de methode een logistisch regressiemodel op de trainingsset. Op een vergelijkbare manier gebruikt het de trainingsgegevens en hetzelfde willekeurige zaad om een Random Forest-model met 100 bomen te initialiseren en te trainen.
Voorspellingen
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Met behulp van de testgegevens en een getraind Logistieke regressie model voorspelt de code de waarschijnlijkheid van de positieve klasse. Op vergelijkbare wijze wordt met behulp van de testgegevens het getrainde Random Forest-model gebruikt om geprojecteerde kansen voor de positieve klasse te produceren.
Een dataframe maken
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Met behulp van de testgegevens creëert de code een DataFrame met de naam test_df met kolommen met de namen True, Logistic en RandomForest, waarbij echte labels en voorspelde kansen uit de Random Forest- en Logistic Regression-modellen worden toegevoegd.
Teken de ROC-curve voor de modellen
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Uitgang:

De code genereert een plot met figuren van 8 bij 6 inch. Het berekent de AUC- en ROC-curve voor elk model (Random Forest en Logistic Regression) en tekent vervolgens de ROC-curve. De ROC-curve voor willekeurig raden wordt ook weergegeven door een rode stippellijn, en labels, een titel en een legenda zijn ingesteld voor visualisatie.
Hoe ROC-AUC gebruiken voor een model met meerdere klassen?
Voor een omgeving met meerdere klassen kunnen we eenvoudigweg één versus alle methodologie gebruiken en beschikt u over één ROC-curve voor elke klasse. Laten we zeggen dat je vier klassen A, B, C en D hebt, dan zouden er ROC-curven en overeenkomstige AUC-waarden zijn voor alle vier klassen, dat wil zeggen dat zodra A één klasse zou zijn en B, C en D samen de andere klasse zouden zijn. Op dezelfde manier is B één klasse en A, C en D gecombineerd als andere klassen, enz.
De algemene stappen voor het gebruik van AUC-ROC in de context van een classificatiemodel met meerdere klassen zijn:
Eén-tegen-alles-methodologie:
- Behandel elke klasse in uw multiklassenprobleem als de positieve klasse en combineer alle andere klassen tot de negatieve klasse.
- Train de binaire classificator voor elke klasse tegen de rest van de klassen.
Bereken AUC-ROC voor elke klasse:
- Hier zetten we de ROC-curve voor de gegeven klasse uit tegen de rest.
- Teken de ROC-curven voor elke klasse in dezelfde grafiek. Elke curve vertegenwoordigt de discriminatieprestaties van het model voor een specifieke klasse.
- Bekijk de AUC-scores voor elke klasse. Een hogere AUC-score duidt op een betere discriminatie voor die specifieke klasse.
Implementatie van AUC-ROC in classificatie met meerdere klassen
Bibliotheken importeren
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Het programma creëert kunstmatige gegevens uit meerdere klassen, verdeelt deze in trainings- en testsets en gebruikt vervolgens de Eén versus restclassifier techniek om classificatoren te trainen voor zowel Random Forest als Logistic Regression. Ten slotte worden de multiklasse ROC-curven van de twee modellen weergegeven om aan te tonen hoe goed ze onderscheid maken tussen verschillende klassen.
Gegevens genereren en splitsen
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Drie klassen en twintig kenmerken vormen de synthetische multiklasse-gegevens die door de code worden geproduceerd. Na labelbinarisatie worden de gegevens verdeeld in trainings- en testsets in een verhouding van 80-20.
Trainingsmodellen
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Het programma traint twee multiklassemodellen: een Random Forest-model met 100 schatters en een Logistic Regressie-model met de Eén-vs-Rest-benadering . Met de trainingsset met gegevens worden beide modellen gefit.
De AUC-ROC-curve uitzetten
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Uitgang:

De ROC-curven en AUC-scores van de Random Forest- en Logistic Regression-modellen worden berekend door de code voor elke klasse. Vervolgens worden de ROC-curven met meerdere klassen uitgezet, waarbij de discriminatieprestaties van elke klasse worden weergegeven en een lijn wordt weergegeven die willekeurig raden weergeeft. De resulterende plot biedt een grafische evaluatie van de classificatieprestaties van de modellen.
Conclusie
Bij machinaal leren worden de prestaties van binaire classificatiemodellen beoordeeld met behulp van een cruciale metriek, de Area Under the Receiver Operating Characteristic (AUC-ROC). Over verschillende beslissingsdrempels heen laat het zien hoe gevoeligheid en specificiteit worden uitgewisseld. Een groter onderscheid tussen positieve en negatieve gevallen wordt doorgaans vertoond door een model met een hogere AUC-score. Terwijl 0,5 toeval aangeeft, staat 1 voor onberispelijke prestaties. Modeloptimalisatie en -selectie worden geholpen door de nuttige informatie die de AUC-ROC-curve biedt over het vermogen van een model om onderscheid te maken tussen klassen. Bij het werken met onevenwichtige datasets of toepassingen waarbij valse positieven en valse negatieven verschillende kosten met zich meebrengen, is dit bijzonder nuttig als alomvattende maatregel.
Veelgestelde vragen over AUC ROC Curve in Machine Learning
1. Wat is de AUC-ROC-curve?
Voor verschillende classificatiedrempels wordt de afweging tussen echt positief percentage (gevoeligheid) en vals positief percentage (specificiteit) grafisch weergegeven door de AUC-ROC-curve.
2. Hoe ziet een perfecte AUC-ROC-curve eruit?
Een oppervlakte van 1 op een ideale AUC-ROC-curve zou betekenen dat het model bij alle drempels optimale gevoeligheid en specificiteit bereikt.
3. Wat betekent een AUC-waarde van 0,5?
Een AUC van 0,5 geeft aan dat de prestaties van het model vergelijkbaar zijn met die van willekeurig toeval. Het duidt op een gebrek aan onderscheidingsvermogen.
4. Kan AUC-ROC worden gebruikt voor classificatie in meerdere klassen?
AUC-ROC wordt vaak toegepast op problemen met binaire classificatie. Variaties zoals de macrogemiddelde of microgemiddelde AUC kunnen in aanmerking worden genomen voor classificatie in meerdere klassen.
5. Hoe is de AUC-ROC-curve nuttig bij modelevaluatie?
Het vermogen van een model om onderscheid te maken tussen klassen wordt uitgebreid samengevat door de AUC-ROC-curve. Bij het werken met onevenwichtige datasets is dit vooral nuttig.