Invoering:
URL-verkorters zijn een voorbeeld van hashing, omdat ze grote URL's toewijzen aan kleine URL's
Enkele voorbeelden van hashfuncties:
- sleutel % aantal buckets
- ASCII-waarde van teken * PrimeNumberX. Waar x = 1, 2, 3….n
- U kunt uw eigen hashfunctie maken, maar het moet een goede hashfunctie zijn die minder botsingen oplevert.
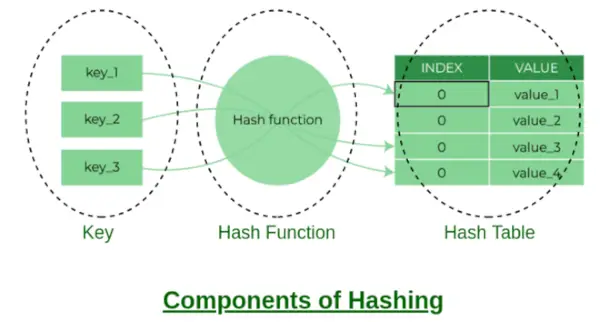
Componenten van hashing
Emmerindex:
De waarde die door de Hash-functie wordt geretourneerd, is de bucketindex voor een sleutel in een afzonderlijke ketenmethode. Elke index in de array wordt een bucket genoemd, omdat het een bucket van een gekoppelde lijst is.
Herhalen:
Rehashing is een concept dat botsingen vermindert wanneer de elementen in de huidige hashtabel worden vergroot. Het zal een nieuwe array van verdubbelde grootte maken en de vorige array-elementen ernaar kopiëren en het is als de interne werking van vector in C++. Het is duidelijk dat de hashfunctie dynamisch moet zijn, omdat deze enkele veranderingen moet weerspiegelen wanneer de capaciteit wordt vergroot. De hashfunctie omvat daarom de capaciteit van de hashtabel, terwijl het kopiëren van sleutelwaarden uit de vorige array de hashfunctie verschillende bucketindexen oplevert, omdat deze afhankelijk is van de capaciteit (buckets) van de hashtabel. Over het algemeen worden er herhashings uitgevoerd als de waarde van de belastingsfactor groter is dan 0,5.
een string omzetten naar een geheel getal
- Verdubbel de grootte van de array.
- Kopieer de elementen van de vorige array naar de nieuwe array. We gebruiken de hash-functie terwijl we elk knooppunt opnieuw naar een nieuwe array kopiëren, waardoor botsingen worden verminderd.
- Verwijder de vorige array uit het geheugen en wijs de interne array-aanwijzer van uw hashkaart naar deze nieuwe array.
- Over het algemeen is de belastingsfactor = aantal elementen in de hashkaart / totaal aantal buckets (capaciteit).
Botsing:
Botsing is de situatie waarin de bucket-index niet leeg is. Het betekent dat er een gekoppelde lijstkop aanwezig is bij die bucketindex. We hebben twee of meer waarden die verwijzen naar dezelfde bucketindex.
Belangrijkste functies in ons programma
- Plaatsing
- Zoekopdracht
- Hash-functie
- Verwijderen
- Herhalen
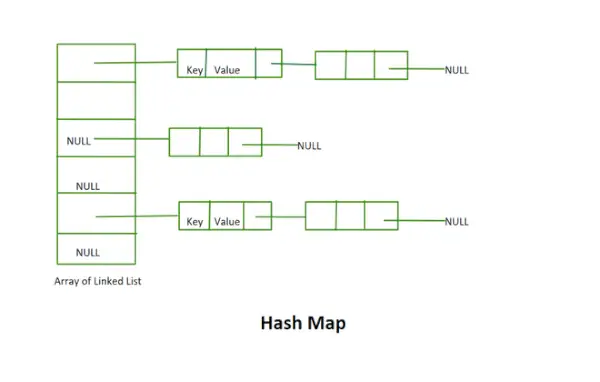
Hash kaart
Implementatie zonder opnieuw te herhalen:
C
sql-gegevenstypen
#include> #include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value)> {> >node->sleutel = sleutel;> >node->waarde = waarde;> >node->volgende = NULL;> >return>;> };> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp)> {> >// Default capacity in this case> >mp->capaciteit = 100;> >mp->aantalElementen = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*)> >* mp->capaciteit);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key)> {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->capaciteit)> >+ (((>int>)key[i]) * factor) % mp->capaciteit)> >% mp->capaciteit;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__)> >* (31 % __INT16_MAX__))> >% __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value)> {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->volgende = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = newNode;> >}> >return>;> }> void> delete> (>struct> hashMap* mp,>char>* key)> {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->sleutel) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->volgende;> >}> >// Last node or middle node> >else> {> >prevNode->next = currNode->volgende;> >}> >free>(currNode);> >break>;> >}> >prevNode = currNode;> >currNode = currNode->volgende;> >}> >return>;> }> char>* search(>struct> hashMap* mp,>char>* key)> {> >// Getting the bucket index> >// for the given key> >int> bucketIndex = hashFunction(mp, key);> >// Head of the linked list> >// present at bucket index> >struct> node* bucketHead = mp->arr[bucketIndex];> >while> (bucketHead != NULL) {> >// Key is found in the hashMap> >if> (bucketHead->sleutel == sleutel) {> >return> bucketHead->waarde;> >}> >bucketHead = bucketHead->volgende;> >}> >// If no key found in the hashMap> >// equal to the given key> >char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> >errorMssg =>'Oops! No data found.
'>;> >return> errorMssg;> }> // Drivers code> int> main()> {> >// Initialize the value of mp> >struct> hashMap* mp> >= (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> >initializeHashMap(mp);> >insert(mp,>'Yogaholic'>,>'Anjali'>);> >insert(mp,>'pluto14'>,>'Vartika'>);> >insert(mp,>'elite_Programmer'>,>'Manish'>);> >insert(mp,>'GFG'>,>'techcodeview.com'>);> >insert(mp,>'decentBoy'>,>'Mayank'>);> >printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> >printf>(>'%s
'>, search(mp,>'Yogaholic'>));> >printf>(>'%s
'>, search(mp,>'pluto14'>));> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >printf>(>'%s
'>, search(mp,>'GFG'>));> >// Key is not inserted> >printf>(>'%s
'>, search(mp,>'randomKey'>));> >printf>(>'
After deletion :
'>);> >// Deletion of key> >delete> (mp,>'decentBoy'>);> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >return> 0;> }> |
>
>
C++
tekenreeks omzetten in geheel getal
Java-structuur
#include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value) {> >node->sleutel = sleutel;> >node->waarde = waarde;> >node->volgende = NULL;> >return>;> }> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp) {> >// Default capacity in this case> >mp->capaciteit = 100;> >mp->aantalElementen = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*) * mp->capaciteit);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key) {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->capaciteit) + (((>int>)key[i]) * factor) % mp->capaciteit) % mp->capaciteit;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value) {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->volgende = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = newNode;> >}> >return>;> }> void> deleteKey(>struct> hashMap* mp,>char>* key) {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->sleutel) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->volgende;> >}> >// Last node or middle node> >else> {> >prevNode->next = currNode->volgende;> }> free>(currNode);> break>;> }> prevNode = currNode;> >currNode = currNode->volgende;> >}> return>;> }> char>* search(>struct> hashMap* mp,>char>* key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > >// Key is found in the hashMap> >if> (>strcmp>(bucketHead->sleutel, sleutel) == 0) {> >return> bucketHead->waarde;> >}> > >bucketHead = bucketHead->volgende;> }> // If no key found in the hashMap equal to the given key> char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> strcpy>(errorMssg,>'Oops! No data found.
'>);> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> initializeHashMap(mp);> insert(mp,>'Yogaholic'>,>'Anjali'>);> insert(mp,>'pluto14'>,>'Vartika'>);> insert(mp,>'elite_Programmer'>,>'Manish'>);> insert(mp,>'GFG'>,>'techcodeview.com'>);> insert(mp,>'decentBoy'>,>'Mayank'>);> printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> printf>(>'%s
'>, search(mp,>'Yogaholic'>));> printf>(>'%s
'>, search(mp,>'pluto14'>));> printf>(>'%s
'>, search(mp,>'decentBoy'>));> printf>(>'%s
'>, search(mp,>'GFG'>));> // Key is not inserted> printf>(>'%s
'>, search(mp,>'randomKey'>));> printf>(>'
After deletion :
'>);> // Deletion of key> deleteKey(mp,>'decentBoy'>);> // Searching the deleted key> printf>(>'%s
'>, search(mp,>'decentBoy'>));> return> 0;> }> |
>
>Uitvoer
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.>
Uitleg:
- invoeging: Voegt het sleutel-waardepaar in aan het hoofd van een gekoppelde lijst die aanwezig is in de gegeven bucketindex. hashFunction: Geeft de bucketindex voor de gegeven sleutel. Ons hash-functie = ASCII-waarde van teken * primeNumberX . Het priemgetal is in ons geval 31 en de waarde van x neemt toe van 1 naar n voor opeenvolgende tekens in een sleutel. verwijderen: Verwijdert het sleutel-waardepaar uit de hashtabel voor de gegeven sleutel. Het verwijdert het knooppunt uit de gekoppelde lijst dat het sleutelwaardepaar bevat. Zoeken: Zoek naar de waarde van de opgegeven sleutel.
- Deze implementatie maakt geen gebruik van het rehashing-concept. Het is een reeks gekoppelde lijsten met een vaste grootte.
- Sleutel en waarde zijn beide strings in het gegeven voorbeeld.
Tijdcomplexiteit en ruimtecomplexiteit:
De tijdscomplexiteit van het invoegen en verwijderen van hashtabellen is gemiddeld O(1). Er is een wiskundige berekening die dit bewijst.
- Tijdcomplexiteit van invoeging: In het gemiddelde geval is het constant. In het ergste geval is het lineair. Tijdscomplexiteit van zoeken: In het gemiddelde geval is het constant. In het ergste geval is het lineair. Tijdscomplexiteit van verwijdering: In gemiddelde gevallen is het constant. In het ergste geval is het lineair. Ruimtecomplexiteit: O(n) omdat het n aantal elementen heeft.
Gerelateerde artikelen:
- Techniek voor het afhandelen van botsingen met afzonderlijke kettingen bij hashing.