Hash-kaarten zijn geïndexeerde datastructuren. Een hashmap maakt gebruik van a hash-functie om een index te berekenen met een sleutel in een array van buckets of slots. De waarde ervan wordt toegewezen aan de bucket met de bijbehorende index. De sleutel is uniek en onveranderlijk. Beschouw een hashmap als een kast met lades met labels voor de spullen die erin zijn opgeslagen. Bij het opslaan van gebruikersinformatie bijvoorbeeld: beschouw e-mail als de sleutel, en we kunnen waarden die overeenkomen met die gebruiker, zoals de voornaam, achternaam enz., toewijzen aan een bucket.
Hash-functie is de kern van het implementeren van een hash-kaart. Het neemt de sleutel op en vertaalt deze naar de index van een bucket in de bucketlist. Ideale hashing zou voor elke sleutel een andere index moeten opleveren. Er kunnen echter botsingen optreden. Wanneer hashen een bestaande index oplevert, kunnen we eenvoudigweg een bucket voor meerdere waarden gebruiken door een lijst toe te voegen of door opnieuw te hashen.
willekeurige waardegenerator in Java
In Python zijn woordenboeken voorbeelden van hash-kaarten. We zullen de implementatie van de hashmap helemaal opnieuw bekijken om te leren hoe we dergelijke datastructuren kunnen bouwen en aanpassen om de zoekopdracht te optimaliseren.
Het hashmapontwerp omvat de volgende functies:
- set_val(sleutel, waarde): Voegt een sleutelwaardepaar in de hashkaart in. Als de waarde al bestaat in de hashkaart, update dan de waarde.
- get_val(sleutel): Retourneert de waarde waaraan de opgegeven sleutel is toegewezen, of Geen record gevonden als deze toewijzing geen toewijzing voor de sleutel bevat.
- verwijder_val(sleutel): Verwijdert de toewijzing voor de specifieke sleutel als de hash-kaart de toewijzing voor de sleutel bevat.
Hieronder vindt u de implementatie.
Python3
class> HashTable:> ># Create empty bucket list of given size> >def> __init__(>self>, size):> >self>.size>=> size> >self>.hash_table>=> self>.create_buckets()> >def> create_buckets(>self>):> >return> [[]>for> _>in> range>(>self>.size)]> ># Insert values into hash map> >def> set_val(>self>, key, val):> > ># Get the index from the key> ># using hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be inserted> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key to be inserted,> ># Update the key value> ># Otherwise append the new key-value pair to the bucket> >if> found_key:> >bucket[index]>=> (key, val)> >else>:> >bucket.append((key, val))> ># Return searched value with specific key> >def> get_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key being searched> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key being searched,> ># Return the value found> ># Otherwise indicate there was no record found> >if> found_key:> >return> record_val> >else>:> >return> 'No record found'> ># Remove a value with specific key> >def> delete_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be deleted> >if> record_key>=>=> key:> >found_key>=> True> >break> >if> found_key:> >bucket.pop(index)> >return> ># To print the items of hash map> >def> __str__(>self>):> >return> ''.join(>str>(item)>for> item>in> self>.hash_table)> hash_table>=> HashTable(>50>)> # insert some values> hash_table.set_val(>'[email protected]'>,>'some value'>)> print>(hash_table)> print>()> hash_table.set_val(>'[email protected]'>,>'some other value'>)> print>(hash_table)> print>()> # search/access a record with key> print>(hash_table.get_val(>'[email protected]'>))> print>()> # delete or remove a value> hash_table.delete_val(>'[email protected]'>)> print>(hash_table)> |
>
>
Uitgang:
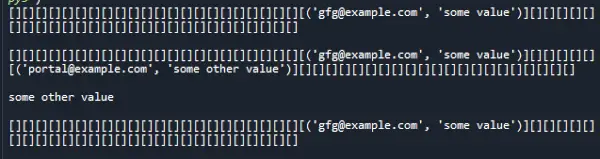
Tijdcomplexiteit:
Toegang tot de geheugenindex kost constante tijd en hashen kost constante tijd. Daarom is de zoekcomplexiteit van een hashkaart ook constante tijd, dat wil zeggen O(1).
Voordelen van HashMaps
● Snelle willekeurige geheugentoegang via hash-functies
● Kan negatieve en niet-integrale waarden gebruiken om toegang te krijgen tot de waarden.
● Sleutels kunnen in gesorteerde volgorde worden opgeslagen en kunnen dus gemakkelijk over de kaarten heen worden herhaald.
Nadelen van HashMaps
● Botsingen kunnen grote gevolgen hebben en de tijdscomplexiteit lineair maken.
● Wanneer het aantal sleutels groot is, veroorzaakt een enkele hashfunctie vaak botsingen.
Toepassingen van HashMaps
● Deze hebben toepassingen in implementaties van Cache waarbij geheugenlocaties worden toegewezen aan kleine sets.
● Ze worden gebruikt om tupels te indexeren in databasebeheersystemen.
scan.nextstring java
● Ze worden ook gebruikt in algoritmen zoals de Rabin Karp-patroonmatching