Neurale netwerken zijn computermodellen die de complexe functies van het menselijk brein nabootsen. De neurale netwerken bestaan uit onderling verbonden knooppunten of neuronen die gegevens verwerken en ervan leren, waardoor taken als patroonherkenning en besluitvorming bij machine learning mogelijk worden. Het artikel gaat dieper in op neurale netwerken, hun werking, architectuur en meer.
Inhoudsopgave
- Evolutie van neurale netwerken
- Wat zijn neurale netwerken?
- Hoe werken neurale netwerken?
- Leren van een neuraal netwerk
- Soorten neurale netwerken
- Eenvoudige implementatie van een neuraal netwerk
Evolutie van neurale netwerken
Sinds de jaren veertig zijn er een aantal opmerkelijke vorderingen gemaakt op het gebied van neurale netwerken:
index van java
- Jaren 40 en 50: vroege concepten
Neurale netwerken begonnen met de introductie van het eerste wiskundige model van kunstmatige neuronen door McCulloch en Pitts. Maar rekenbeperkingen maakten vooruitgang moeilijk.
- Jaren 60 en 70: Perceptrons
Dit tijdperk wordt bepaald door het werk van Rosenblatt over perceptrons. Perceptronen zijn enkellaagsnetwerken waarvan de toepasbaarheid beperkt was tot problemen die lineair afzonderlijk konden worden opgelost.
- Jaren 80: Backpropagation en Connectionisme
Meerlaags netwerk training werd mogelijk gemaakt door de uitvinding van de backpropagation-methode door Rumelhart, Hinton en Williams. Met de nadruk op leren via onderling verbonden knooppunten won het connectionisme aan populariteit.
- Jaren negentig: boom en winter
Met toepassingen op het gebied van beeldidentificatie, financiën en andere terreinen kenden neurale netwerken een enorme bloei. Het onderzoek naar neurale netwerken kende echter een winter als gevolg van exorbitante computerkosten en te hoge verwachtingen.
- Jaren 2000: heropleving en diepgaand leren
Grotere datasets, innovatieve structuren en verbeterde verwerkingsmogelijkheden zorgden voor een comeback. Diep leren heeft in een aantal disciplines verbazingwekkende effectiviteit getoond door gebruik te maken van talloze lagen.
- 2010-heden: dominantie van diepgaand leren
Convolutionele neurale netwerken (CNN's) en terugkerende neurale netwerken (RNN's), twee deep learning-architecturen, domineerden machine learning. Hun kracht werd gedemonstreerd door innovaties op het gebied van gaming, beeldherkenning en natuurlijke taalverwerking.
Wat zijn neurale netwerken?
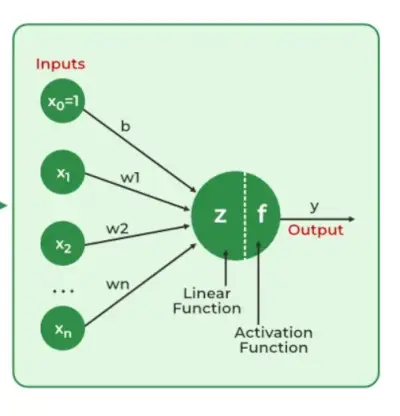
Neurale netwerken identificerende kenmerken uit gegevens halen, zonder voorgeprogrammeerd begrip. Netwerkcomponenten omvatten neuronen, verbindingen, gewichten, vooroordelen, voortplantingsfuncties en een leerregel. Neuronen ontvangen input, bepaald door drempels en activeringsfuncties. Verbindingen brengen gewichten en vooroordelen met zich mee die de informatieoverdracht reguleren. Leren, het aanpassen van gewichten en vooroordelen, vindt plaats in drie fasen: inputberekening, outputgeneratie en iteratieve verfijning, waardoor de vaardigheid van het netwerk in diverse taken wordt vergroot.
Deze omvatten:
- Het neurale netwerk wordt gesimuleerd door een nieuwe omgeving.
- Vervolgens worden de vrije parameters van het neurale netwerk gewijzigd als resultaat van deze simulatie.
- Het neurale netwerk reageert dan op een nieuwe manier op de omgeving vanwege de veranderingen in zijn vrije parameters.
Belang van neurale netwerken
Het vermogen van neurale netwerken om patronen te identificeren, ingewikkelde puzzels op te lossen en zich aan te passen aan veranderende omgevingen is essentieel. Hun vermogen om van data te leren heeft verstrekkende gevolgen, variërend van een revolutie in de technologie natuurlijke taalverwerking en zelfrijdende auto’s tot het automatiseren van besluitvormingsprocessen en het verhogen van de efficiëntie in tal van industrieën. De ontwikkeling van kunstmatige intelligentie is grotendeels afhankelijk van neurale netwerken, die ook innovatie aandrijven en de richting van de technologie beïnvloeden.
Hoe werken neurale netwerken?
Laten we een voorbeeld geven van hoe een neuraal netwerk werkt:
Overweeg een neuraal netwerk voor e-mailclassificatie. De invoerlaag bevat functies zoals e-mailinhoud, afzenderinformatie en onderwerp. Deze invoer, vermenigvuldigd met aangepaste gewichten, gaat door verborgen lagen. Het netwerk leert door training patronen te herkennen die aangeven of een e-mail spam is of niet. De uitvoerlaag, met een binaire activeringsfunctie, voorspelt of de e-mail spam is (1) of niet (0). Naarmate het netwerk iteratief zijn gewicht verfijnt door middel van backpropagation, wordt het bedreven in het maken van onderscheid tussen spam en legitieme e-mails, wat de bruikbaarheid van neurale netwerken in echte toepassingen zoals e-mailfiltering aantoont.
Werking van een neuraal netwerk
Neurale netwerken zijn complexe systemen die bepaalde kenmerken van het functioneren van het menselijk brein nabootsen. Het bestaat uit een invoerlaag, een of meer verborgen lagen en een uitvoerlaag die bestaat uit lagen van kunstmatige neuronen die met elkaar zijn gekoppeld. De twee fasen van het basisproces worden backpropagatie en genoemd voorwaartse voortplanting .
Voorwaartse voortplanting
- Invoerlaag: Elk kenmerk in de invoerlaag wordt vertegenwoordigd door een knooppunt op het netwerk, dat invoergegevens ontvangt.
- Gewichten en aansluitingen: Het gewicht van elke neuronale verbinding geeft aan hoe sterk de verbinding is. Tijdens de training worden deze gewichten gewijzigd.
- Verborgen lagen: Elk neuron in de verborgen laag verwerkt input door deze met gewichten te vermenigvuldigen, op te tellen en vervolgens door een activeringsfunctie te leiden. Door dit te doen wordt niet-lineariteit geïntroduceerd, waardoor het netwerk ingewikkelde patronen kan herkennen.
- Uitgang: Het eindresultaat wordt geproduceerd door het proces te herhalen totdat de uitvoerlaag is bereikt.
Terugpropagatie
- Verliesberekening: De output van het netwerk wordt geëvalueerd aan de hand van de werkelijke doelwaarden, en een verliesfunctie wordt gebruikt om het verschil te berekenen. Voor een regressieprobleem wordt de Gemiddelde kwadratische fout (MSE) wordt vaak gebruikt als kostenfunctie.
Verliesfunctie:
- Gradiënt afdaling: Gradiëntdaling wordt vervolgens door het netwerk gebruikt om het verlies te verminderen. Om de onnauwkeurigheid te verminderen, worden de gewichten gewijzigd op basis van de afgeleide van het verlies met betrekking tot elk gewicht.
- Gewichten aanpassen: De gewichten worden bij elke verbinding aangepast door dit iteratieve proces toe te passen, of terugpropagatie , achteruit over het netwerk.
- Opleiding: Tijdens het trainen met verschillende datamonsters wordt het hele proces van voorwaartse voortplanting, verliesberekening en achterwaartse voortplanting iteratief uitgevoerd, waardoor het netwerk zich kan aanpassen en patronen uit de gegevens kan leren.
- Activeringsfuncties: Niet-lineariteit van modellen wordt geïntroduceerd door activeringsfuncties zoals de gelijkgerichte lineaire eenheid (ReLU) uur sigmoïd . Hun beslissing over het al dan niet afvuren van een neuron is gebaseerd op de gehele gewogen input.

Leren van een neuraal netwerk
1. Leren met begeleid leren
In leren onder toezicht wordt het neurale netwerk geleid door een leraar die toegang heeft tot beide input-output-paren. Het netwerk creëert output op basis van input, zonder rekening te houden met de omgeving. Door deze uitgangen te vergelijken met de door de docent bekende gewenste uitgangen wordt een foutsignaal gegenereerd. Om fouten te verminderen, worden de parameters van het netwerk iteratief gewijzigd en stoppen ze wanneer de prestaties op een acceptabel niveau zijn.
2. Leren met leren zonder toezicht
Equivalente outputvariabelen ontbreken in ongecontroleerd leren . Het belangrijkste doel is om de onderliggende structuur van binnenkomende gegevens (X) te begrijpen. Er is geen instructeur aanwezig die advies kan geven. In plaats daarvan is het modelleren van datapatronen en relaties het beoogde resultaat. Woorden als regressie en classificatie houden verband met leren onder toezicht, terwijl leren zonder toezicht verband houdt met clustering en associatie.
3. Leren met versterkend leren
Door interactie met de omgeving en feedback in de vorm van beloningen of straffen verwerft het netwerk kennis. Het doel van het netwerk is het vinden van een beleid of strategie die de cumulatieve beloningen in de loop van de tijd optimaliseert. Dit soort wordt vaak gebruikt in gaming- en besluitvormingstoepassingen.
gelinkte lijst java
Soorten neurale netwerken
Er zijn zeven soorten neurale netwerken die kunnen worden gebruikt.
wat is svn afrekenen
- Feedforward-netwerken: A feedforward neuraal netwerk is een eenvoudige kunstmatige neurale netwerkarchitectuur waarin gegevens in één richting van invoer naar uitvoer bewegen. Het heeft invoer-, verborgen- en uitvoerlagen; feedbackloops ontbreken. De eenvoudige architectuur maakt het geschikt voor een aantal toepassingen, zoals regressie en patroonherkenning.
- Meerlaags Perceptron (MLP): MLP is een type feedforward neuraal netwerk met drie of meer lagen, waaronder een invoerlaag, een of meer verborgen lagen en een uitvoerlaag. Het maakt gebruik van niet-lineaire activeringsfuncties.
- Convolutioneel Neuraal Netwerk (CNN): A Convolutioneel Neuraal Netwerk (CNN) is een gespecialiseerd kunstmatig neuraal netwerk ontworpen voor beeldverwerking. Het maakt gebruik van convolutionele lagen om automatisch hiërarchische kenmerken van invoerbeelden te leren, waardoor effectieve beeldherkenning en classificatie mogelijk wordt. CNN's hebben een revolutie teweeggebracht in computervisie en zijn cruciaal bij taken als objectdetectie en beeldanalyse.
- Terugkerend neuraal netwerk (RNN): Een kunstmatig neuraal netwerktype bedoeld voor sequentiële gegevensverwerking wordt a genoemd Terugkerend neuraal netwerk (RNN). Het is geschikt voor toepassingen waarbij contextuele afhankelijkheden van cruciaal belang zijn, zoals tijdreeksvoorspelling en natuurlijke taalverwerking, omdat het gebruik maakt van feedbackloops, waardoor informatie binnen het netwerk kan overleven.
- Lange kortetermijngeheugen (LSTM): LSTM is een type RNN dat is ontworpen om het verdwijnende gradiëntprobleem bij het trainen van RNN's te overwinnen. Het maakt gebruik van geheugencellen en poorten om selectief informatie te lezen, schrijven en wissen.
Eenvoudige implementatie van een neuraal netwerk
Python3
import> numpy as np> # array of any amount of numbers. n = m> X>=> np.array([[>1>,>2>,>3>],> >[>3>,>4>,>1>],> >[>2>,>5>,>3>]])> # multiplication> y>=> np.array([[.>5>, .>3>, .>2>]])> # transpose of y> y>=> y.T> # sigma value> sigm>=> 2> # find the delta> delt>=> np.random.random((>3>,>3>))>-> 1> for> j>in> range>(>100>):> > ># find matrix 1. 100 layers.> >m1>=> (y>-> (>1>/>(>1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt))))))>*>((>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))>*>(>1>->(>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))))> ># find matrix 2> >m2>=> m1.dot(delt.T)>*> ((>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> >*> (>1>->(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))))> ># find delta> >delt>=> delt>+> (>1>/>(>1> +> np.exp(>->(np.dot(X, sigm))))).T.dot(m1)> ># find sigma> >sigm>=> sigm>+> (X.T.dot(m2))> # print output from the matrix> print>(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> |
>
>
Uitgang:
[[0.99999325 0.99999375 0.99999352] [0.99999988 0.99999989 0.99999988] [1. 1. 1. ]]>
Voordelen van neurale netwerken
Neurale netwerken worden veel gebruikt in veel verschillende toepassingen vanwege hun vele voordelen:
- Aanpassingsvermogen: Neurale netwerken zijn nuttig voor activiteiten waarbij de link tussen input en output complex is of niet goed gedefinieerd, omdat ze zich kunnen aanpassen aan nieuwe situaties en van gegevens kunnen leren.
- Patroonherkenning: Hun vaardigheid in patroonherkenning maakt ze effectief in taken zoals audio- en beeldidentificatie, natuurlijke taalverwerking en andere ingewikkelde gegevenspatronen.
- Parallelle verwerking: Omdat neurale netwerken van nature in staat zijn tot parallelle verwerking, kunnen ze talloze taken tegelijk verwerken, wat de efficiëntie van berekeningen versnelt en verbetert.
- Niet-lineariteit: Neurale netwerken zijn in staat gecompliceerde relaties in gegevens te modelleren en te begrijpen dankzij de niet-lineaire activeringsfuncties die in neuronen worden aangetroffen, waardoor de nadelen van lineaire modellen worden ondervangen.
Nadelen van neurale netwerken
Neurale netwerken zijn weliswaar krachtig, maar zijn niet zonder nadelen en moeilijkheden:
- Computationele intensiteit: Het trainen van grote neurale netwerken kan een arbeidsintensief en rekenintensief proces zijn dat veel rekenkracht vereist.
- Zwarte doos Aard: Als black box-modellen vormen neurale netwerken een probleem bij belangrijke toepassingen, omdat het moeilijk te begrijpen is hoe ze beslissingen nemen.
- Overfitting: Overfitting is een fenomeen waarbij neurale netwerken trainingsmateriaal in het geheugen opslaan in plaats van patronen in de gegevens te identificeren. Hoewel regularisatiebenaderingen dit helpen verlichten, bestaat het probleem nog steeds.
- Behoefte aan grote datasets: Voor efficiënte training hebben neurale netwerken vaak omvangrijke, gelabelde datasets nodig; anders kunnen hun prestaties te lijden hebben onder onvolledige of scheve gegevens.
Veelgestelde vragen (FAQ's)
1. Wat is een neuraal netwerk?
Een neuraal netwerk is een kunstmatig systeem gemaakt van onderling verbonden knooppunten (neuronen) die informatie verwerken, gemodelleerd naar de structuur van het menselijk brein. Het wordt gebruikt in machine learning-banen waarbij patronen uit gegevens worden gehaald.
2. Hoe werkt een neuraal netwerk?
Lagen van verbonden neuronen verwerken gegevens in neurale netwerken. Het netwerk verwerkt invoergegevens, wijzigt gewichten tijdens de training en produceert uitvoer afhankelijk van de patronen die het heeft ontdekt.
3. Wat zijn de meest voorkomende typen neurale netwerkarchitecturen?
Feedforward neurale netwerken, recurrente neurale netwerken (RNN's), convolutionele neurale netwerken (CNN's) en lange kortetermijngeheugennetwerken (LSTM's) zijn voorbeelden van gemeenschappelijke architecturen die elk zijn ontworpen voor een bepaalde taak.
4. Wat is het verschil tussen begeleid en onbewaakt leren in neurale netwerken?
Bij gesuperviseerd leren worden gelabelde gegevens gebruikt om een neuraal netwerk te trainen, zodat het kan leren inputs aan bijpassende outputs toe te wijzen. Unsupervised learning werkt met ongelabelde data en zoekt naar structuren of patronen in de data .
5. Hoe gaan neurale netwerken om met sequentiële gegevens?
De feedbacklussen die terugkerende neurale netwerken (RNN's) bevatten, stellen hen in staat sequentiële gegevens te verwerken en in de loop van de tijd afhankelijkheden en context vast te leggen.