Met Pandas.apply kunnen gebruikers een functie doorgeven en deze toepassen op elke afzonderlijke waarde van de Pandas-serie. Het is een enorme verbetering voor de Panda's-bibliotheek, omdat deze functie helpt gegevens te scheiden op basis van de vereiste omstandigheden waardoor deze efficiënt worden gebruikt in datawetenschap en machinaal leren.
Installatie:
Importeer de Pandas-module in het Python-bestand met behulp van de volgende opdrachten op de terminal:
pip install pandas>
Om het csv-bestand te lezen en in een panda-serie te persen, worden de volgende opdrachten gebruikt:
import pandas as pd s = pd.read_csv('stock.csv', squeeze=True)> Syntaxis:
s.apply(func, convert_dtype=True, args=())>
Parameters:
func: .apply neemt een functie en past deze toe op alle waarden van pandareeksen. convert_dtype: Converteer dtype volgens de werking van de functie. args=(): Aanvullende argumenten die moeten worden doorgegeven aan de functie in plaats van aan reeksen. Retourtype: Pandas-serie na toegepaste functie/bediening.
Voorbeeld 1:
Het volgende voorbeeld geeft een functie door en controleert de waarde van elk element in serie en retourneert dienovereenkomstig laag, normaal of hoog.
PYTHON3
import> pandas as pd> # reading csv> s>=> pd.read_csv('stock.csv', squeeze>=> True>)> # defining function to check price> def> fun(num):> >if> num<>200>:> >return> 'Low'> >elif> num>>=> 200> and> num<>400>:> >return> 'Normal'> >else>:> >return> 'High'> # passing function to apply and storing returned series in new> new>=> s.>apply>(fun)> # printing first 3 element> print>(new.head(>3>))> # printing elements somewhere near the middle of series> print>(new[>1400>], new[>1500>], new[>1600>])> # printing last 3 elements> print>(new.tail(>3>))> |
np std
>
>
Uitgang:
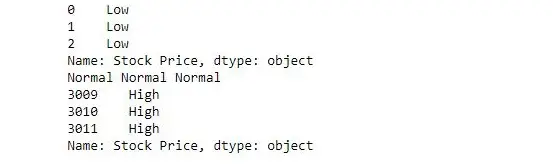
Voorbeeld #2:
In het volgende voorbeeld wordt een tijdelijke anonieme functie gemaakt in .apply zelf met behulp van lambda. Het voegt 5 toe aan elke waarde in reeksen en retourneert een nieuwe reeks.
PYTHON3
import> pandas as pd> s>=> pd.read_csv('stock.csv', squeeze>=> True>)> # adding 5 to each value> new>=> s.>apply>(>lambda> num : num>+> 5>)> # printing first 5 elements of old and new series> print>(s.head(),>'
'>, new.head())> # printing last 5 elements of old and new series> print>(>'
'>, s.tail(),>'
'>, new.tail())> |
>
>
Uitgang:
0 50.12 1 54.10 2 54.65 3 52.38 4 52.95 Name: Stock Price, dtype: float64 0 55.12 1 59.10 2 59.65 3 57.38 4 57.95 Name: Stock Price, dtype: float64 3007 772.88 3008 771.07 3009 773.18 3010 771.61 3011 782.22 Name: Stock Price, dtype: float64 3007 777.88 3008 776.07 3009 778.18 3010 776.61 3011 787.22 Name: Stock Price, dtype: float64>
Zoals waargenomen: Nieuwe waarden = oude waarden + 5