BERT, een acroniem voor bidirectionele encoderrepresentaties van Transformers , staat als een open source raamwerk voor machinaal leren ontworpen voor het rijk van natuurlijke taalverwerking (NLP) . Dit raamwerk, afkomstig uit 2018, is gemaakt door onderzoekers van Google AI Language. Het artikel heeft tot doel de architectuur, werking en toepassingen van BERT .
Wat is BERT?
BERT (Bidirectionele Encoder-representaties van Transformers) maakt gebruik van een op transformatoren gebaseerd neuraal netwerk om mensachtige taal te begrijpen en te genereren. BERT maakt gebruik van een architectuur die alleen bestaat uit encoders. In het origineel Transformator-architectuur , er zijn zowel encoder- als decodermodules. De beslissing om in BERT een architectuur met alleen encoders te gebruiken suggereert dat de nadruk vooral ligt op het begrijpen van invoerreeksen in plaats van op het genereren van uitvoerreeksen.
Bidirectionele aanpak van BERT
Traditionele taalmodellen verwerken tekst opeenvolgend, van links naar rechts of van rechts naar links. Deze methode beperkt het bewustzijn van het model tot de onmiddellijke context voorafgaand aan het doelwoord. BERT gebruikt een bidirectionele aanpak waarbij zowel de linker- als de rechtercontext van woorden in een zin in aanmerking wordt genomen. In plaats van de tekst opeenvolgend te analyseren, kijkt BERT tegelijkertijd naar alle woorden in een zin.
Voorbeeld: De oever ligt aan de _______ van de rivier.
In een unidirectioneel model zou het begrip van de blanco in grote mate afhangen van de voorgaande woorden, en zou het model moeite kunnen hebben om te onderscheiden of bank verwijst naar een financiële instelling of naar de kant van de rivier.
Omdat BERT bidirectioneel is, houdt het tegelijkertijd rekening met zowel de linker (de oever ligt aan de) als de rechter context (van de rivier), waardoor een genuanceerder begrip mogelijk wordt. Het begrijpt dat het ontbrekende woord waarschijnlijk verband houdt met de geografische locatie van de bank, wat de contextuele rijkdom aantoont die de bidirectionele aanpak met zich meebrengt.
Voortraining en finetuning
Het BERT-model ondergaat een proces in twee stappen:
- Vooropleiding over grote hoeveelheden ongelabelde tekst om contextuele insluitingen te leren.
- Verfijning van gelabelde gegevens voor specifiek NLP taken.
Vooropleiding over grote data
- BERT is vooraf getraind in een grote hoeveelheid ongelabelde tekstgegevens. Het model leert contextuele inbedding, dit zijn de representaties van woorden die rekening houden met hun omringende context in een zin.
- BERT houdt zich bezig met verschillende pre-trainingstaken zonder toezicht. Het kan bijvoorbeeld ontbrekende woorden in een zin leren voorspellen (Masked Language Model of MLM-taak), de relatie tussen twee zinnen begrijpen of de volgende zin in een paar voorspellen.
Verfijning van gelabelde gegevens
- Na de pre-trainingsfase wordt het BERT-model, gewapend met zijn contextuele inbedding, vervolgens verfijnd voor specifieke taken op het gebied van natuurlijke taalverwerking (NLP). Deze stap stemt het model af op meer gerichte toepassingen door het algemene taalbegrip aan te passen aan de nuances van de specifieke taak.
- BERT wordt verfijnd met behulp van gelabelde gegevens die specifiek zijn voor de downstream-taken van belang. Deze taken kunnen bestaan uit sentimentanalyse, het beantwoorden van vragen, benoemde entiteitsherkenning , of een andere NLP-toepassing. De parameters van het model worden aangepast om de prestaties ervan te optimaliseren voor de specifieke vereisten van de uit te voeren taak.
Dankzij de uniforme architectuur van BERT kan het zich met minimale aanpassingen aanpassen aan verschillende downstream-taken, waardoor het een veelzijdig en zeer effectief hulpmiddel is in natuurlijk taalbegrip en verwerking.
Hoe werkt BERT?
BERT is ontworpen om een taalmodel te genereren, dus alleen het encodermechanisme wordt gebruikt. De reeks tokens wordt naar de Transformer-encoder gevoerd. Deze tokens worden eerst ingebed in vectoren en vervolgens verwerkt in het neurale netwerk. De uitvoer is een reeks vectoren, die elk overeenkomen met een invoertoken, waardoor gecontextualiseerde representaties worden geboden.
Bij het trainen van taalmodellen is het definiëren van een voorspellingsdoel een uitdaging. Veel modellen voorspellen het volgende woord in een reeks, wat een directionele benadering is en het contextleren kan beperken. BERT gaat deze uitdaging aan met twee innovatieve trainingsstrategieën:
- Gemaskeerd taalmodel (MLM)
- Voorspelling van volgende zin (NSP)
1. Gemaskeerd taalmodel (MLM)
In het pre-trainingsproces van BERT wordt een deel van de woorden in elke invoerreeks gemaskeerd en wordt het model getraind om de oorspronkelijke waarden van deze gemaskeerde woorden te voorspellen op basis van de context die door de omringende woorden wordt geboden.
In simpele termen,
- Maskerende woorden: Voordat BERT van zinnen leert, verbergt het enkele woorden (ongeveer 15%) en vervangt deze door een speciaal symbool, zoals [MASK].
- Verborgen woorden raden: Het is de taak van BERT om erachter te komen wat deze verborgen woorden zijn door naar de woorden om hen heen te kijken. Het is als een spelletje raden waar sommige woorden ontbreken, en BERT probeert de lege plekken in te vullen.
- Hoe BERT leert:
- BERT voegt een speciale laag toe bovenop zijn leersysteem om deze gissingen te maken. Vervolgens controleert het hoe dicht zijn gissingen bij de daadwerkelijke verborgen woorden liggen.
- Het doet dit door zijn gissingen om te zetten in waarschijnlijkheden, door te zeggen: ik denk dat dit woord X is, en ik ben er zo zeker van.
- Speciale aandacht voor verborgen woorden
- De belangrijkste focus van BERT tijdens de training ligt op het correct krijgen van deze verborgen woorden. Het geeft minder om het voorspellen van de woorden die niet verborgen zijn.
- Dit komt omdat de echte uitdaging het uitzoeken van de ontbrekende delen is, en deze strategie helpt BERT echt goed te worden in het begrijpen van de betekenis en context van woorden.
In technische termen,
- BERT voegt een classificatielaag toe bovenop de uitvoer van de encoder. Deze laag is cruciaal voor het voorspellen van de gemaskeerde woorden.
- De uitvoervectoren van de classificatielaag worden vermenigvuldigd met de inbeddingsmatrix, waardoor ze worden getransformeerd in de woordenschatdimensie. Deze stap helpt bij het uitlijnen van de voorspelde representaties met de woordenschatruimte.
- De waarschijnlijkheid van elk woord in de woordenschat wordt berekend met behulp van de SoftMax-activeringsfunctie . Deze stap genereert voor elke gemaskeerde positie een waarschijnlijkheidsverdeling over het gehele vocabulaire.
- De verliesfunctie die tijdens de training wordt gebruikt, houdt alleen rekening met de voorspelling van de gemaskeerde waarden. Het model wordt bestraft voor de afwijking tussen zijn voorspellingen en de werkelijke waarden van de gemaskeerde woorden.
- Het model convergeert langzamer dan directionele modellen. Dit komt omdat BERT tijdens de training alleen bezig is met het voorspellen van de gemaskeerde waarden, waarbij de voorspelling van de niet-gemaskeerde woorden wordt genegeerd. Het toegenomen contextbewustzijn dat door deze strategie wordt bereikt, compenseert de langzamere convergentie.
2. Voorspelling van de volgende zin (NSP)
BERT voorspelt of de tweede zin verband houdt met de eerste. Dit wordt gedaan door de uitvoer van het [CLS]-token te transformeren in een 2×1-vormige vector met behulp van een classificatielaag, en vervolgens de waarschijnlijkheid te berekenen of de tweede zin de eerste volgt met behulp van SoftMax.
- Tijdens het trainingsproces leert BERT de relatie tussen zinnenparen te begrijpen, door te voorspellen of de tweede zin volgt op de eerste in het originele document.
- 50% van de invoerparen heeft de tweede zin als de volgende zin in het originele document, en de overige 50% heeft een willekeurig gekozen zin.
- Om het model te helpen onderscheid te maken tussen verbonden en niet-verbonden zinsparen. De invoer wordt verwerkt voordat het model wordt ingevoerd:
- Aan het begin van de eerste zin wordt een [CLS]-token ingevoegd en aan het einde van elke zin een [SEP]-token.
- Aan elk token wordt een zininbedding toegevoegd die Zin A of Zin B aangeeft.
- Een positionele inbedding geeft de positie van elk token in de reeks aan.
- BERT voorspelt of de tweede zin verband houdt met de eerste. Dit wordt gedaan door de uitvoer van het [CLS]-token te transformeren in een 2×1-vormige vector met behulp van een classificatielaag, en vervolgens de waarschijnlijkheid te berekenen of de tweede zin de eerste volgt met behulp van SoftMax.
Tijdens de training van het BERT-model worden de Masked LM en Next Sentence Prediction samen getraind. Het model heeft tot doel de gecombineerde verliesfunctie van de Masked LM en Next Sentence Prediction te minimaliseren, wat leidt tot een robuust taalmodel met verbeterde mogelijkheden voor het begrijpen van de context binnen zinnen en relaties tussen zinnen.
Waarom Masked LM en Next Sentence Prediction samen trainen?
Gemaskeerde LM helpt BERT de context binnen een zin te begrijpen Voorspelling van de volgende zin helpt BERT het verband of de relatie tussen zinnenparen te begrijpen. Het samen trainen van beide strategieën zorgt er dus voor dat BERT een breed en alomvattend begrip van taal leert, waarbij zowel details in zinnen als de stroom tussen zinnen worden vastgelegd.
BERT-architecturen
De architectuur van BERT is een meerlaagse bidirectionele transformator-encoder die vrij gelijkaardig is aan het transformatormodel. Een transformatorarchitectuur is een encoder-decodernetwerk dat gebruik maakt van zelf-aandacht aan de encoderzijde en aandacht aan de decoderzijde.
- BERTBASERENheeft 1 2 lagen in de Encoder-stack terwijl BERTGROOTheeft 24 lagen in de Encoder-stack . Dit zijn meer dan de Transformer-architectuur die in het originele artikel wordt beschreven ( 6 encoderlagen ).
- BERT-architecturen (BASE en LARGE) hebben ook grotere feedforward-netwerken (respectievelijk 768 en 1024 verborgen eenheden), en meer aandachtshoofden (respectievelijk 12 en 16) dan de Transformer-architectuur die in het originele artikel werd voorgesteld. Het bevat 512 verborgen eenheden en 8 aandachtshoofden .
- BERTBASERENbevat 110M parameters terwijl BERTGROOTheeft 340M-parameters.

BERT BASE en BERT LARGE architectuur.
Dit model neemt de CLS token eerst als invoer, daarna wordt het gevolgd door een reeks woorden als invoer. CLS is hier een classificatietoken. Vervolgens geeft het de invoer door aan de bovenstaande lagen. Elke laag is van toepassing zelf-aandacht en geeft het resultaat door via een feedforward-netwerk, waarna het wordt doorgegeven aan de volgende encoder. Het model voert een vector met verborgen grootte uit ( 768 voor BERTBASE). Als we een classificator uit dit model willen uitvoeren, kunnen we de uitvoer nemen die overeenkomt met het CLS-token.
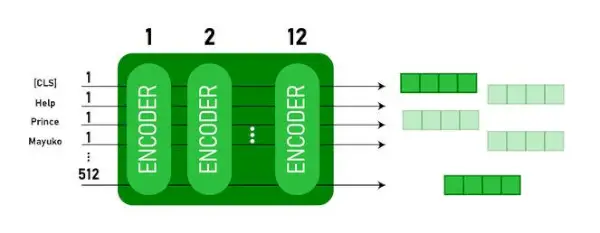
BERT-uitvoer als insluitingen
Nu kan deze getrainde vector worden gebruikt om een aantal taken uit te voeren, zoals classificatie, vertaling, enz. Het papier behaalt bijvoorbeeld geweldige resultaten door slechts één enkele laag te gebruiken Neuraal netwerk op het BERT-model in de classificatietaak.
Hoe gebruik je het BERT-model in NLP?
BERT kan worden gebruikt voor verschillende natuurlijke taalverwerkingstaken (NLP), zoals:
1. Classificatietaak
- BERT kan worden gebruikt voor classificatietaken zoals sentiment analyse , het doel is om de tekst in verschillende categorieën te classificeren (positief/negatief/neutraal), BERT kan worden gebruikt door een classificatielaag toe te voegen bovenaan de Transformer-uitvoer voor het [CLS]-token.
- Het [CLS]-token vertegenwoordigt de geaggregeerde informatie uit de gehele invoerreeks. Deze gepoolde representatie kan vervolgens worden gebruikt als invoer voor een classificatielaag om voorspellingen te doen voor de specifieke taak.
2. Vraag beantwoorden
- Bij het beantwoorden van vragen, waarbij het model het antwoord binnen een bepaalde tekstreeks moet lokaliseren en markeren, kan BERT voor dit doel worden getraind.
- BERT is getraind in het beantwoorden van vragen door twee extra vectoren te leren die het begin en het einde van het antwoord markeren. Tijdens de training wordt het model voorzien van vragen en bijbehorende passages en leert het de begin- en eindposities van het antwoord binnen de passage te voorspellen.
3. Erkenning van benoemde entiteiten (NER)
- BERT kan worden gebruikt voor NER, waarbij het doel is om entiteiten (bijvoorbeeld persoon, organisatie, datum) in een tekstreeks te identificeren en te classificeren.
- Een op BERT gebaseerd NER-model wordt getraind door de uitvoervector van elk token uit de Transformer te nemen en deze in een classificatielaag in te voeren. De laag voorspelt het benoemde entiteitslabel voor elk token, waarbij het type entiteit wordt aangegeven dat het vertegenwoordigt.
Hoe tekst tokeniseren en coderen met BERT?
Om tekst te tokeniseren en te coderen met BERT, zullen we de ‘transformer’-bibliotheek in Python gebruiken.
Commando om transformatoren te installeren:
!pip install transformers>
- We zullen de voorgetrainde BERT-tokenize laden met een vocabulaire in hoofdletters met behulp van BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(tekst) tokeniseert de invoertekst en converteert deze naar een reeks token-ID's.
- print(Token-ID's:, codering) drukt de token-ID's af die zijn verkregen na het coderen.
- tokenizer.convert_ids_to_tokens(codering) converteert de token-ID's terug naar hun overeenkomstige tokens.
- print(Tokens:, tokens) drukt de tokens af die zijn verkregen na het converteren van de token-ID's
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Uitgang:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> De tokenizer.encode methode voegt de special toe [CLS] – classificatie En [SEP] – scheidingsteken tokens aan het begin en einde van de gecodeerde reeks.
Toepassing van BERT
BERT wordt gebruikt voor:
- Tekstrepresentatie: BERT wordt gebruikt om woordinsluitingen of representatie van woorden in een zin te genereren.
- Erkenning van benoemde entiteiten (NER) : BERT kan worden verfijnd voor taken voor het herkennen van benoemde entiteiten, waarbij het doel is om entiteiten zoals namen van mensen, organisaties, locaties, enz. in een bepaalde tekst te identificeren.
- Tekstclassificatie: BERT wordt veel gebruikt voor tekstclassificatietaken, waaronder sentimentanalyse, spamdetectie en onderwerpcategorisatie. Het heeft uitstekende prestaties geleverd bij het begrijpen en classificeren van de context van tekstuele gegevens.
- Vraag-antwoordsystemen: BERT is toegepast op vraag-antwoordsystemen, waarbij het model is getraind om de context van een vraag te begrijpen en relevante antwoorden te geven. Dit is vooral handig voor taken zoals begrijpend lezen.
- Machine vertaling: De contextuele inbedding van BERT kan worden ingezet voor het verbeteren van automatische vertaalsystemen. Het model legt de nuances van de taal vast die cruciaal zijn voor een nauwkeurige vertaling.
- Samenvatting van de tekst: BERT kan worden gebruikt voor abstracte samenvattingen van teksten, waarbij het model beknopte en betekenisvolle samenvattingen van langere teksten genereert door de context en semantiek te begrijpen.
- Conversatie-AI: BERT wordt gebruikt bij het bouwen van conversatie-AI-systemen, zoals chatbots, virtuele assistenten en dialoogsystemen. Het vermogen om context te begrijpen maakt het effectief voor het begrijpen en genereren van natuurlijke taalreacties.
- Semantische gelijkenis: BERT-inbedding kan worden gebruikt om de semantische gelijkenis tussen zinnen of documenten te meten. Dit is waardevol bij taken zoals duplicaatdetectie, parafrase-identificatie en het ophalen van informatie.
BERT versus GPT
Het verschil tussen BERT en GPT is als volgt:
| BERT | GPT | |
|---|---|---|
| Architectuur | BERT is ontworpen voor bidirectioneel representatieleren. Het maakt gebruik van een gemaskeerd taalmodel, waarbij het ontbrekende woorden in een zin voorspelt op basis van zowel de linker- als de rechtercontext. | GPT is daarentegen ontworpen voor generatieve taalmodellering. Het voorspelt het volgende woord in een zin, gegeven de voorgaande context, met behulp van een unidirectionele autoregressieve benadering. |
| Doelstellingen vóór de training | BERT is vooraf getraind met behulp van een gemaskeerd taalmodeldoelstelling en voorspelling van de volgende zin. Het richt zich op het vastleggen van bidirectionele context en het begrijpen van relaties tussen woorden in een zin. | GPT is vooraf getraind om het volgende woord in een zin te voorspellen, wat het model aanmoedigt om een coherente representatie van taal te leren en contextueel relevante reeksen te genereren. |
| Contextbegrip | BERT is effectief voor taken die een diepgaand begrip van de context en relaties binnen een zin vereisen, zoals tekstclassificatie, herkenning van benoemde entiteiten en het beantwoorden van vragen. | GPT is sterk in het genereren van samenhangende en contextueel relevante tekst. Het wordt vaak gebruikt bij creatieve taken, dialoogsystemen en taken die het genereren van natuurlijke taalsequenties vereisen. |
| Taaktypen en gebruiksscenario's
| Wordt vaak gebruikt bij taken zoals tekstclassificatie, herkenning van benoemde entiteiten, sentimentanalyse en het beantwoorden van vragen. | Toegepast op taken zoals het genereren van tekst, dialoogsystemen, samenvattingen en creatief schrijven. |
| Verfijning versus leren met weinig schoten | BERT wordt vaak verfijnd op specifieke downstream-taken met gelabelde gegevens om de vooraf getrainde representaties aan te passen aan de uit te voeren taak. | GPT is ontworpen om in een paar stappen te leren, waarbij het kan generaliseren naar nieuwe taken met minimale taakspecifieke trainingsgegevens. |
Controleer ook:
- Sentimentclassificatie met behulp van BERT
- Hoe kan ik Word-inbedding genereren met BERT?
- BART-model voor automatische voltooiing van tekst in NLP
- Toxische commentaarclassificatie met behulp van BERT
- Voorspelling van de volgende zin met BERT
Veelgestelde vragen (FAQ's)
V. Waar wordt BERT voor gebruikt?
BERT wordt gebruikt voor het uitvoeren van NLP-taken zoals tekstrepresentatie, herkenning van benoemde entiteiten, tekstclassificatie, vraag- en antwoordsystemen, automatische vertaling, tekstsamenvatting en meer.
V. Wat zijn de voordelen van het BERT-model?
Het BERT-taalmodel onderscheidt zich door zijn uitgebreide vooropleiding in meerdere talen en biedt een brede taalkundige dekking in vergelijking met andere modellen. Dit maakt BERT bijzonder voordelig voor niet-Engelstalige projecten, omdat het robuuste contextuele representaties en semantisch begrip biedt in een breed scala aan talen, waardoor de veelzijdigheid ervan in meertalige toepassingen wordt vergroot.
V. Hoe werkt BERT voor sentimentanalyse?
BERT blinkt uit in sentimentanalyse door gebruik te maken van zijn bidirectionele representatie en leert contextuele nuances, semantische betekenissen en syntactische structuren binnen een bepaalde tekst vast te leggen. Hierdoor kan BERT het sentiment begrijpen dat in een zin wordt uitgedrukt door de relaties tussen woorden in ogenschouw te nemen, wat resulteert in zeer effectieve resultaten van sentimentanalyse.
c-codearray van tekenreeksen
V. Is Google gebaseerd op BERT?
BERT En RangBrain zijn componenten van het zoekalgoritme van Google om zoekopdrachten en webpagina-inhoud te verwerken om een beter begrip te krijgen en de zoekresultaten te verbeteren.