In de echte wereld hebben niet alle gegevens waarmee we werken een doelvariabele. Dit soort gegevens kunnen niet worden geanalyseerd met behulp van begeleide leeralgoritmen. We hebben de hulp nodig van algoritmen zonder toezicht. Een van de meest populaire soorten analyses onder onbegeleid leren is klantsegmentatie voor gerichte advertenties, of bij medische beeldvorming om onbekende of nieuwe geïnfecteerde gebieden te vinden en nog veel meer gebruiksscenario's die we verder in dit artikel zullen bespreken.
Inhoudsopgave
- Wat is clusteren?
- Soorten clustering
- Gebruik van clustering
- Soorten clusteralgoritmen
- Toepassingen van clustering op verschillende gebieden:
- Veelgestelde vragen (FAQ's) over clustering
Wat is clusteren?
De taak van het groeperen van datapunten op basis van hun gelijkenis met elkaar wordt Clustering of Clusteranalyse genoemd. Deze methode is gedefinieerd onder de tak van Ongecontroleerd leren , dat tot doel heeft inzichten te verkrijgen uit niet-gelabelde datapunten, dat wil zeggen, in tegenstelling tot leren onder toezicht we hebben geen doelvariabele.
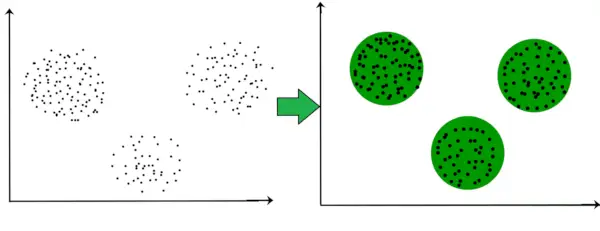
Clustering is gericht op het vormen van groepen homogene datapunten uit een heterogene dataset. Het evalueert de gelijkenis op basis van een metriek zoals Euclidische afstand, Cosinus-gelijkenis, Manhattan-afstand, enz. en groepeert vervolgens de punten met de hoogste gelijkenisscore samen.
In de onderstaande grafiek kunnen we bijvoorbeeld duidelijk zien dat er zich drie cirkelvormige clusters vormen op basis van de afstand.
lexicografische volgorde
Nu is het niet nodig dat de gevormde clusters cirkelvormig van vorm moeten zijn. De vorm van clusters kan willekeurig zijn. Er zijn veel algoritmen die goed werken bij het detecteren van willekeurig gevormde clusters.
In de onderstaande grafiek kunnen we bijvoorbeeld zien dat de gevormde clusters niet cirkelvormig zijn.

Soorten clustering
Globaal gesproken zijn er twee soorten clustering die kunnen worden uitgevoerd om vergelijkbare datapunten te groeperen:
- Harde clustering: Bij dit type clustering behoort elk datapunt al dan niet volledig tot een cluster. Laten we bijvoorbeeld zeggen dat er vier datapunten zijn en dat we deze in twee clusters moeten clusteren. Elk datapunt behoort dus tot cluster 1 of tot cluster 2.
| Data punten | Clusters |
|---|---|
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Zachte clustering: Bij dit type clustering wordt, in plaats van elk datapunt in een afzonderlijk cluster toe te wijzen, de waarschijnlijkheid of waarschijnlijkheid dat dat punt dat cluster is, geëvalueerd. Laten we bijvoorbeeld zeggen dat er vier datapunten zijn en dat we deze in twee clusters moeten clusteren. We zullen dus de waarschijnlijkheid evalueren van een datapunt dat tot beide clusters behoort. Deze waarschijnlijkheid wordt voor alle datapunten berekend.
| Data punten | Waarschijnlijkheid van C1 | Waarschijnlijkheid van C2 |
| A | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Gebruik van clustering
Voordat we beginnen met soorten clusteralgoritmen, zullen we de gebruiksscenario's van clusteralgoritmen doornemen. Clusteralgoritmen worden voornamelijk gebruikt voor:
statisch trefwoord in Java
- Marktaandeel – Bedrijven gebruiken clustering om hun klanten te groeperen en gebruiken gerichte advertenties om meer publiek aan te trekken.
- Analyse van sociale netwerken – Sociale-mediasites gebruiken uw gegevens om uw surfgedrag te begrijpen en u gerichte vriendenaanbevelingen of inhoudsaanbevelingen te bieden.
- Medische beeldvorming – Artsen gebruiken Clustering om zieke gebieden te ontdekken in diagnostische beelden zoals röntgenfoto’s.
- Onregelmatigheidsdetectie – Om uitschieters te vinden in een stroom realtime datasets of om frauduleuze transacties te voorspellen, kunnen we clustering gebruiken om ze te identificeren.
- Vereenvoudig het werken met grote datasets – Elk cluster krijgt een cluster-ID nadat de clustering is voltooid. Nu kunt u de gehele functieset van een functieset reduceren tot de cluster-ID. Clustering is effectief als het een ingewikkeld geval kan vertegenwoordigen met een duidelijke cluster-ID. Met hetzelfde principe kan het clusteren van gegevens complexe datasets eenvoudiger maken.
Er zijn nog veel meer gebruiksscenario's voor clustering, maar er zijn enkele van de belangrijkste en meest voorkomende gebruiksscenario's van clustering. In de toekomst zullen we clusteralgoritmen bespreken die u zullen helpen de bovenstaande taken uit te voeren.
Soorten clusteralgoritmen
Op het oppervlakniveau helpt clustering bij de analyse van ongestructureerde gegevens. Grafieken, de kortste afstand en de dichtheid van de datapunten zijn enkele van de elementen die clustervorming beïnvloeden. Clustering is het proces waarbij wordt bepaald hoe gerelateerd de objecten zijn, op basis van een metriek die de gelijkenismaatstaf wordt genoemd. Overeenstemmingsstatistieken zijn gemakkelijker te vinden in kleinere sets functies. Het wordt moeilijker om overeenkomsten te meten naarmate het aantal kenmerken toeneemt. Afhankelijk van het type clusteralgoritme dat wordt gebruikt bij datamining, worden verschillende technieken gebruikt om de gegevens uit de datasets te groeperen. In dit deel worden de clustertechnieken beschreven. Er zijn verschillende soorten clusteralgoritmen:
- Centroid-gebaseerde clustering (partitioneringsmethoden)
- Op dichtheid gebaseerde clustering (modelgebaseerde methoden)
- Op connectiviteit gebaseerde clustering (hiërarchische clustering)
- Op distributie gebaseerde clustering
We zullen elk van deze typen kort bespreken.
1. Partitioneringsmethoden zijn de gemakkelijkste clusteralgoritmen. Ze groeperen gegevenspunten op basis van hun nabijheid. Over het algemeen is de overeenkomstmaatstaf die voor deze algoritmen wordt gekozen de Euclidische afstand, Manhattan-afstand of Minkowski-afstand. De datasets zijn onderverdeeld in een vooraf bepaald aantal clusters, en naar elk cluster wordt verwezen door een vector van waarden. Vergeleken met de vectorwaarde vertoont de invoergegevensvariabele geen verschil en voegt hij zich bij het cluster.
Het belangrijkste nadeel van deze algoritmen is de vereiste dat we het aantal clusters, k, intuïtief of wetenschappelijk (met behulp van de Elbow-methode) moeten vaststellen voordat een machine learning-systeem voor clustering begint met het toewijzen van de datapunten. Desondanks is het nog steeds de meest populaire vorm van clustering. K-betekent En K-medicijnen clustering zijn enkele voorbeelden van dit type clustering.
2. Op dichtheid gebaseerde clustering (modelgebaseerde methoden)
Op dichtheid gebaseerde clustering, een op modellen gebaseerde methode, vindt groepen op basis van de dichtheid van datapunten. In tegenstelling tot op zwaartepunten gebaseerde clustering, waarbij het aantal clusters vooraf moet worden gedefinieerd en gevoelig is voor initialisatie, bepaalt op dichtheid gebaseerde clustering automatisch het aantal clusters en is deze minder gevoelig voor beginposities. Ze zijn uitstekend in het verwerken van clusters van verschillende groottes en vormen, waardoor ze bij uitstek geschikt zijn voor datasets met onregelmatig gevormde of overlappende clusters. Deze methoden beheren zowel dichte als schaarse datagebieden door zich te concentreren op de lokale dichtheid en kunnen clusters met verschillende morfologieën onderscheiden.
Daarentegen heeft op zwaartepunten gebaseerde groepering, zoals k-means, moeite met het vinden van willekeurig gevormde clusters. Vanwege het vooraf ingestelde aantal clustervereisten en de extreme gevoeligheid voor de initiële positionering van zwaartepunten kunnen de uitkomsten variëren. Bovendien beperkt de neiging van op zwaartepunten gebaseerde benaderingen om bolvormige of convexe clusters te produceren hun vermogen om gecompliceerde of onregelmatig gevormde clusters te verwerken. Concluderend overwint op dichtheid gebaseerde clustering de nadelen van centroid-gebaseerde technieken door autonoom clustergroottes te kiezen, veerkrachtig te zijn tegen initialisatie en met succes clusters van verschillende groottes en vormen vast te leggen. Het meest populaire op dichtheid gebaseerde clusteralgoritme is DBSCAN .
3. Op connectiviteit gebaseerde clustering (hiërarchische clustering)
Een methode voor het samenstellen van gerelateerde gegevenspunten in hiërarchische clusters wordt hiërarchische clustering genoemd. Elk datapunt wordt in eerste instantie beschouwd als een afzonderlijk cluster, dat vervolgens wordt gecombineerd met de clusters die het meest op elkaar lijken om één groot cluster te vormen dat alle datapunten bevat.
Bedenk hoe u een verzameling items kunt ordenen op basis van hoe vergelijkbaar ze zijn. Elk object begint als zijn eigen cluster aan de basis van de boom bij gebruik van hiërarchische clustering, waardoor een dendrogram ontstaat, een boomachtige structuur. De dichtstbijzijnde clusterparen worden vervolgens gecombineerd tot grotere clusters nadat het algoritme heeft onderzocht hoe vergelijkbaar de objecten met elkaar zijn. Wanneer elk object zich in één cluster bovenaan de boom bevindt, is het samenvoegproces voltooid. Het verkennen van verschillende granulariteitsniveaus is een van de leuke dingen van hiërarchische clustering. Om een bepaald aantal clusters te verkrijgen, kunt u ervoor kiezen om de clusters te knippen dendrogram op een bepaalde hoogte. Hoe meer twee objecten op elkaar lijken binnen een cluster, hoe dichter ze bij elkaar liggen. Het is vergelijkbaar met het classificeren van items op basis van hun stamboom, waarbij de dichtstbijzijnde verwanten bij elkaar zijn geclusterd en de bredere takken meer algemene verbindingen aangeven. Er zijn twee benaderingen voor hiërarchische clustering:
- Verdeeldheidwekkende clustering : Het volgt een top-down benadering, hier beschouwen we alle datapunten als onderdeel van één groot cluster en vervolgens wordt dit cluster in kleinere groepen verdeeld.
- Agglomeratieve clustering : Het volgt een bottom-up benadering, hier beschouwen we alle datapunten als onderdeel van individuele clusters en vervolgens worden deze clusters samengevoegd om één groot cluster met alle datapunten te vormen.
4. Op distributie gebaseerde clustering
Met behulp van op distributie gebaseerde clustering worden gegevenspunten gegenereerd en georganiseerd op basis van hun neiging om binnen de gegevens in dezelfde waarschijnlijkheidsverdeling (zoals een Gaussiaanse, binominale of andere) te vallen. De gegevenselementen worden gegroepeerd met behulp van een op waarschijnlijkheid gebaseerde verdeling die is gebaseerd op statistische verdelingen. Inbegrepen zijn gegevensobjecten waarvan de kans groter is dat ze zich in het cluster bevinden. Het is minder waarschijnlijk dat een datapunt in een cluster wordt opgenomen naarmate het verder verwijderd is van het centrale punt van het cluster, dat in elk cluster voorkomt.
Een opmerkelijk nadeel van op dichtheid en grenzen gebaseerde benaderingen is de noodzaak om de clusters a priori te specificeren voor sommige algoritmen, en in de eerste plaats de definitie van de clustervorm voor het merendeel van de algoritmen. Er moet ten minste één afstemmings- of hyperparameter zijn geselecteerd, en hoewel dit eenvoudig moet zijn, kan een foutieve afstemming onverwachte gevolgen hebben. Op distributie gebaseerde clustering heeft een duidelijk voordeel ten opzichte van nabijheids- en zwaartepuntgebaseerde clusterbenaderingen in termen van flexibiliteit, nauwkeurigheid en clusterstructuur. Het belangrijkste probleem is dat, om te voorkomen overfitting , werken veel clustermethoden alleen met gesimuleerde of vervaardigde gegevens, of wanneer het grootste deel van de gegevenspunten zeker tot een vooraf ingestelde distributie behoort. Het populairste op distributie gebaseerde clusteralgoritme is Gaussiaans mengselmodel .
Toepassingen van clustering op verschillende gebieden:
- Marketing: Het kan worden gebruikt om klantsegmenten te karakteriseren en te ontdekken voor marketingdoeleinden.
- Biologie: Het kan worden gebruikt voor classificatie tussen verschillende soorten planten en dieren.
- Bibliotheken: Het wordt gebruikt bij het clusteren van verschillende boeken op basis van onderwerpen en informatie.
- Verzekering: Het wordt gebruikt om de klanten, hun beleid te erkennen en de fraude te identificeren.
- Stadsplanning: Het wordt gebruikt om groepen huizen te maken en hun waarden te bestuderen op basis van hun geografische locatie en andere aanwezige factoren.
- Aardbevingsstudies: Door de door aardbevingen getroffen gebieden te leren kennen, kunnen we de gevaarlijke zones bepalen.
- Afbeelding verwerken : Clustering kan worden gebruikt om vergelijkbare afbeeldingen te groeperen, afbeeldingen te classificeren op basis van inhoud en patronen in afbeeldingsgegevens te identificeren.
- Genetica: Clustering wordt gebruikt om genen te groeperen die vergelijkbare expressiepatronen hebben en gennetwerken te identificeren die samenwerken in biologische processen.
- Financiën: Clustering wordt gebruikt om marktsegmenten te identificeren op basis van klantgedrag, patronen in aandelenmarktgegevens te identificeren en risico's in beleggingsportefeuilles te analyseren.
- Klantenservice: Clustering wordt gebruikt om vragen en klachten van klanten in categorieën te groeperen, gemeenschappelijke problemen te identificeren en gerichte oplossingen te ontwikkelen.
- Productie : Clustering wordt gebruikt om vergelijkbare producten te groeperen, productieprocessen te optimaliseren en defecten in productieprocessen te identificeren.
- Medische diagnose: Clustering wordt gebruikt om patiënten met vergelijkbare symptomen of ziekten te groeperen, wat helpt bij het stellen van nauwkeurige diagnoses en het identificeren van effectieve behandelingen.
- Fraude detectie: Clustering wordt gebruikt om verdachte patronen of afwijkingen in financiële transacties te identificeren, wat kan helpen bij het opsporen van fraude of andere financiële misdrijven.
- Verkeersanalyse: Clustering wordt gebruikt om vergelijkbare patronen van verkeersgegevens te groeperen, zoals piekuren, routes en snelheden, wat kan helpen bij het verbeteren van de transportplanning en infrastructuur.
- Analyse van sociale netwerken: Clustering wordt gebruikt om gemeenschappen of groepen binnen sociale netwerken te identificeren, wat kan helpen bij het begrijpen van sociaal gedrag, invloed en trends.
- Cyberbeveiliging: Clustering wordt gebruikt om vergelijkbare patronen van netwerkverkeer of systeemgedrag te groeperen, wat kan helpen bij het detecteren en voorkomen van cyberaanvallen.
- Klimaatanalyse: Clustering wordt gebruikt om vergelijkbare patronen van klimaatgegevens, zoals temperatuur, neerslag en wind, te groeperen, wat kan helpen bij het begrijpen van de klimaatverandering en de impact ervan op het milieu.
- Sportanalyse: Clustering wordt gebruikt om vergelijkbare patronen van prestatiegegevens van spelers of teams te groeperen, wat kan helpen bij het analyseren van de sterke en zwakke punten van spelers of teams en het nemen van strategische beslissingen.
- Misdaadanalyse: Clustering wordt gebruikt om vergelijkbare patronen van misdaadgegevens te groeperen, zoals locatie, tijd en type, wat kan helpen bij het identificeren van hotspots van misdaad, het voorspellen van toekomstige misdaadtrends en het verbeteren van misdaadpreventiestrategieën.
Conclusie
In dit artikel hebben we Clustering besproken, de typen ervan en de toepassingen ervan in de echte wereld. Er valt nog veel meer te bespreken op het gebied van onbegeleid leren en clusteranalyse is slechts de eerste stap. Dit artikel kan u helpen aan de slag te gaan met Clustering-algoritmen en u helpen een nieuw project te krijgen dat aan uw portfolio kan worden toegevoegd.
Veelgestelde vragen (FAQ's) over clustering
V. Wat is de beste clustermethode?
De top 10 clusteralgoritmen zijn:
- K-betekent Clustering
- Hiërarchische clustering
- DBSCAN (op dichtheid gebaseerde ruimtelijke clustering van toepassingen met ruis)
- Gaussiaanse mengselmodellen (GMM)
- Agglomeratieve clustering
- Spectrale clustering
- Mean Shift-clustering
- Affiniteitsvoortplanting
- OPTICS (bestelpunten om de clusterstructuur te identificeren)
- Birch (gebalanceerd iteratief reduceren en clusteren met behulp van hiërarchieën)
V. Wat is het verschil tussen clustering en classificatie?
Het belangrijkste verschil tussen clustering en classificatie is dat classificatie een leeralgoritme onder toezicht is en clustering een leeralgoritme zonder toezicht. Dat wil zeggen dat we clustering toepassen op die datasets die geen doelvariabele hebben.
panda's iterrijen
V. Wat zijn de voordelen van clusteranalyse?
Gegevens kunnen in betekenisvolle groepen worden georganiseerd met behulp van het sterke analytische hulpmiddel clusteranalyse. U kunt het gebruiken om segmenten te lokaliseren, verborgen patronen te vinden en beslissingen te verbeteren.
V. Wat is de snelste clustermethode?
K-means clustering wordt vaak beschouwd als de snelste clustermethode vanwege de eenvoud en rekenefficiëntie. Het wijst iteratief datapunten toe aan het dichtstbijzijnde clusterzwaartepunt, waardoor het geschikt is voor grote datasets met lage dimensionaliteit en een gematigd aantal clusters.
V. Wat zijn de beperkingen van clustering?
Beperkingen van clustering zijn onder meer gevoeligheid voor initiële omstandigheden, afhankelijkheid van de keuze van parameters, problemen bij het bepalen van het optimale aantal clusters en uitdagingen bij het verwerken van hoogdimensionale of luidruchtige gegevens.
V. Waar hangt de kwaliteit van het resultaat van clustering van af?
De kwaliteit van clusterresultaten hangt af van factoren zoals de keuze van het algoritme, de afstandsmetriek, het aantal clusters, de initialisatiemethode, technieken voor gegevensvoorverwerking, clusterevaluatiemetrieken en domeinkennis. Deze elementen beïnvloeden gezamenlijk de effectiviteit en nauwkeurigheid van het clusterresultaat.