We lezen de lineaire datastructuren zoals een array, gekoppelde lijst, stapel en wachtrij waarin alle elementen opeenvolgend zijn gerangschikt. De verschillende datastructuren worden gebruikt voor verschillende soorten gegevens.
Bij het kiezen van de datastructuur wordt rekening gehouden met enkele factoren:
Een boom is ook een van de datastructuren die hiërarchische gegevens vertegenwoordigen. Stel dat we de werknemers en hun posities in de hiërarchische vorm willen weergeven, dan kan dit als volgt worden weergegeven:
tekenreekswaardevan
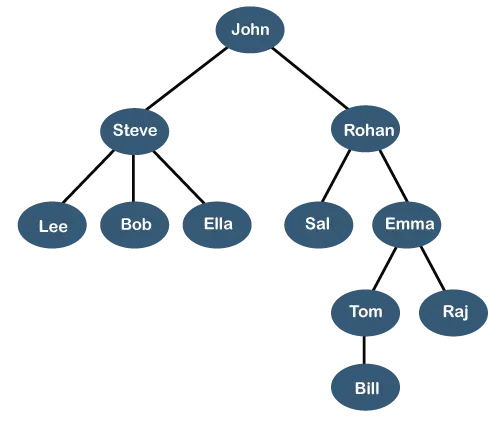
De bovenstaande boom toont de hiërarchie van de organisatie van een of ander bedrijf. In de bovenstaande structuur is John is de Directeur van het bedrijf, en John heeft twee directe ondergeschikten genaamd Steve En Rohan . Steve heeft drie directe ondergeschikten genoemd Lee, Bob, Ella waar Steve is een beheerder. Bob heeft twee directe ondergeschikten genoemd Zullen En Emma . Emma heeft twee directe ondergeschikten Tom En Raj . Tom heeft één directe ondergeschikte genoemd Rekening . Deze specifieke logische structuur staat bekend als a Boom . De structuur is vergelijkbaar met de echte boom, daarom wordt hij a genoemd Boom . In deze structuur is de wortel bevindt zich bovenaan en de takken bewegen in neerwaartse richting. Daarom kunnen we zeggen dat de Tree-gegevensstructuur een efficiënte manier is om de gegevens op een hiërarchische manier op te slaan.
Laten we enkele belangrijke punten van de boomgegevensstructuur begrijpen.
- Een boomgegevensstructuur wordt gedefinieerd als een verzameling objecten of entiteiten die bekend staan als knooppunten en die met elkaar zijn verbonden om de hiërarchie weer te geven of te simuleren.
- Een boomdatastructuur is een niet-lineaire datastructuur omdat deze niet op een sequentiële manier wordt opgeslagen. Het is een hiërarchische structuur, omdat elementen in een boom op meerdere niveaus zijn gerangschikt.
- In de boomgegevensstructuur staat het bovenste knooppunt bekend als een hoofdknooppunt. Elk knooppunt bevat een aantal gegevens en gegevens kunnen van elk type zijn. In de bovenstaande boomstructuur bevat het knooppunt de naam van de werknemer, dus het type gegevens zou een string zijn.
- Elk knooppunt bevat enkele gegevens en de link of referentie van andere knooppunten die kinderen kunnen worden genoemd.
Enkele basistermen die worden gebruikt in de boomgegevensstructuur.
Laten we eens kijken naar de boomstructuur, die hieronder wordt weergegeven:

In de bovenstaande structuur is elk knooppunt gelabeld met een nummer. Elke pijl in de bovenstaande afbeelding staat bekend als a koppeling tussen de twee knooppunten.
Eigenschappen van boomgegevensstructuur

Op basis van de eigenschappen van de boomgegevensstructuur worden bomen in verschillende categorieën ingedeeld.
Implementatie van Boom
De boomdatastructuur kan worden gecreëerd door de knooppunten dynamisch te creëren met behulp van de pointers. De boom in het geheugen kan worden weergegeven zoals hieronder weergegeven:

De bovenstaande afbeelding toont de weergave van de boomdatastructuur in het geheugen. In de bovenstaande structuur bevat het knooppunt drie velden. In het tweede veld worden de gegevens opgeslagen; in het eerste veld wordt het adres van het linkerkind opgeslagen, en in het derde veld het adres van het rechterkind.
Bij het programmeren kan de structuur van een knooppunt als volgt worden gedefinieerd:
struct node { int data; struct node *left; struct node *right; } De bovenstaande structuur kan alleen worden gedefinieerd voor de binaire bomen, omdat de binaire boom maximaal twee kinderen kan hebben, en generieke bomen meer dan twee kinderen kunnen hebben. De structuur van het knooppunt voor generieke bomen zou anders zijn dan die van de binaire boom.
Toepassingen van bomen
Hieronder volgen de toepassingen van bomen:
gelinkte lijst java
Typen boomgegevensstructuur
Hieronder volgen de typen boomgegevensstructuren:

Er kan zijn N aantal subbomen in een algemene boom. In de algemene boom zijn de subbomen ongeordend omdat de knooppunten in de subboom niet kunnen worden geordend.
Elke niet-lege boom heeft een neerwaartse rand, en deze randen zijn verbonden met de zogenaamde knooppunten onderliggende knooppunten . Het hoofdknooppunt is gelabeld met niveau 0. De knooppunten die dezelfde ouder hebben, staan bekend als broers of zussen .

Als u meer wilt weten over de binaire boom, klikt u op de onderstaande link:
https://www.javatpoint.com/binary-tree
Elk knooppunt in de linker subboom moet een waarde bevatten die kleiner is dan de waarde van het hoofdknooppunt, en de waarde van elk knooppunt in de rechter subboom moet groter zijn dan de waarde van het hoofdknooppunt.
Een knooppunt kan worden gemaakt met behulp van een door de gebruiker gedefinieerd gegevenstype dat bekend staat als structureren, zoals hieronder weergegeven:
struct node { int data; struct node *left; struct node *right; } Het bovenstaande is de knooppuntstructuur met drie velden: gegevensveld, het tweede veld is de linkeraanwijzer van het knooppunttype en het derde veld is de rechteraanwijzer van het knooppunttype.
boto3
Om meer te weten te komen over de binaire zoekboom, klikt u op de onderstaande link:
https://www.javatpoint.com/binary-search-tree
Het is een van de typen van de binaire boom, of we kunnen zeggen dat het een variant is van de binaire zoekboom. AVL-boom voldoet aan de eigenschap van de binaire boom evenals van de binaire zoekboom . Het is een zelfbalancerende binaire zoekboom die is uitgevonden door Adelson Velsky Lindas . Zelfbalancering betekent hier het in evenwicht brengen van de hoogten van de linker deelboom en de rechter deelboom. Deze balans wordt gemeten in termen van de balancerende factor .
We kunnen een boom als een AVL-boom beschouwen als de boom zowel aan de binaire zoekboom als aan een evenwichtsfactor voldoet. De balanceringsfactor kan worden gedefinieerd als de verschil tussen de hoogte van de linker deelboom en de hoogte van de rechter deelboom . De waarde van de balanceringsfactor moet 0, -1 of 1 zijn; daarom moet elk knooppunt in de AVL-boom de waarde van de balanceringsfactor hebben als 0, -1 of 1.
Als u meer wilt weten over de AVL-boom, klikt u op de onderstaande link:
https://www.javatpoint.com/avl-tree
samengestelde primaire sleutel
De rood-zwarte boom is de binaire zoekboom. De voorwaarde voor de rood-zwarte boom is dat we kennis moeten hebben van de binaire zoekboom. In een binaire zoekboom moet de waarde van de linkersubboom kleiner zijn dan de waarde van dat knooppunt, en de waarde van de rechtersubboom moet groter zijn dan de waarde van dat knooppunt. Zoals we weten is de tijdscomplexiteit van binair zoeken in het gemiddelde geval log2n, het beste geval is O(1), en het slechtste geval is O(n).
Wanneer er een bewerking in de boom wordt uitgevoerd, willen we dat onze boom in balans is, zodat alle bewerkingen zoals zoeken, invoegen, verwijderen, enz. minder tijd in beslag nemen, en al deze bewerkingen de tijdscomplexiteit zullen hebben van loggen2N.
De rood-zwarte boom is een zelfbalancerende binaire zoekboom. De AVL-boom is dan ook een binaire zoekboom voor hoogtebalancering waarom hebben we een rood-zwarte boom nodig? . In de AVL-boom weten we niet hoeveel rotaties nodig zijn om de boom in evenwicht te brengen, maar in de rood-zwarte boom zijn maximaal 2 rotaties nodig om de boom in evenwicht te brengen. Het bevat een extra bit dat de rode of zwarte kleur van een knooppunt vertegenwoordigt om de balans van de boom te garanderen.
De splay tree-gegevensstructuur is ook een binaire zoekboom waarin recentelijk benaderde elementen op de hoofdpositie van de boom worden geplaatst door enkele rotatiebewerkingen uit te voeren. Hier, spreiden betekent het recentelijk bezochte knooppunt. Het is een zelfbalancerend binaire zoekboom zonder expliciete evenwichtsvoorwaarde zoals AVL boom.
Het zou een mogelijkheid kunnen zijn dat de hoogte van de splay tree niet in evenwicht is, d.w.z. de hoogte van zowel de linker als de rechter subboom kan verschillen, maar de bewerkingen in de splay tree nemen de volgorde aan van kalm tijd waar N is het aantal knooppunten.
De Splay-boom is een uitgebalanceerde boom, maar kan niet worden beschouwd als een in hoogte gebalanceerde boom, omdat na elke bewerking een rotatie wordt uitgevoerd die leidt tot een uitgebalanceerde boom.
De Treap-gegevensstructuur kwam voort uit de Tree- en Heap-gegevensstructuur. Het omvat dus de eigenschappen van zowel Tree- als Heap-datastructuren. In de binaire zoekboom moet elk knooppunt in de linker subboom gelijk zijn aan of kleiner zijn dan de waarde van het hoofdknooppunt en moet elk knooppunt in de rechter subboom gelijk zijn aan of groter zijn dan de waarde van het hoofdknooppunt. In de heap-datastructuur bevatten zowel de rechter als de linker subboom grotere sleutels dan de root; daarom kunnen we zeggen dat het hoofdknooppunt de laagste waarde bevat.
In de treap-datastructuur heeft elk knooppunt beide sleutel En prioriteit waarbij de sleutel is afgeleid van de binaire zoekboom en de prioriteit is afgeleid van de heap-gegevensstructuur.
De Treap De datastructuur volgt twee eigenschappen die hieronder worden gegeven:
- Rechter kind van een knooppunt>=huidig knooppunt en linker kind van een knooppunt<=current node (binary tree)< li>
- Kinderen van een subboom moeten groter zijn dan het knooppunt (heap)
B-boom is een evenwichtige m-weg boom waar M bepaalt de volgorde van de boom. Tot nu toe hebben we gelezen dat het knooppunt slechts één sleutel bevat, maar b-tree kan meer dan één sleutel hebben, en meer dan 2 kinderen. Het behoudt altijd de gesorteerde gegevens. In een binaire boom is het mogelijk dat bladknooppunten zich op verschillende niveaus kunnen bevinden, maar in b-boom moeten alle bladknooppunten zich op hetzelfde niveau bevinden.
collecties Java
Als de volgorde m is, heeft het knooppunt de volgende eigenschappen:
- Elk knooppunt in een b-boom kan een maximum hebben M kinderen
- Voor minimale kinderen heeft een bladknooppunt 0 kinderen, heeft het wortelknooppunt minimaal 2 kinderen en heeft het interne knooppunt een minimumplafond van m/2 kinderen. De waarde van m is bijvoorbeeld 5, wat betekent dat een knooppunt 5 kinderen kan hebben en dat interne knooppunten maximaal 3 kinderen kunnen bevatten.
- Elk knooppunt heeft maximale sleutels (m-1).
Het hoofdknooppunt moet minimaal 1 sleutel bevatten en alle andere knooppunten moeten er minimaal 1 bevatten plafond van m/2 min 1 sleutels.