In het besturingssysteem moesten we de invoer aan de CPU geven, en de CPU voert de instructies uit en geeft uiteindelijk de uitvoer. Maar er was een probleem met deze aanpak. In een normale situatie hebben we te maken met veel processen, en we weten dat de tijd die nodig is voor de I/O-bewerking erg groot is vergeleken met de tijd die de CPU nodig heeft voor het uitvoeren van de instructies. Dus in de oude aanpak zal één proces de invoer geven met behulp van een invoerapparaat, en gedurende deze tijd bevindt de CPU zich in een inactieve toestand.
java do while-lus
Vervolgens voert de CPU de instructie uit, en de uitvoer wordt opnieuw aan een uitvoerapparaat gegeven, en op dit moment bevindt de CPU zich ook in een inactieve toestand. Nadat de uitvoer is weergegeven, begint het volgende proces met de uitvoering ervan. Dus meestal is de CPU inactief, wat de ergste toestand is die we kunnen hebben in besturingssystemen. Hier komt het concept van spoolen om de hoek kijken.
Wat is spoelen
Spoolen is een proces waarbij gegevens tijdelijk worden vastgehouden om te worden gebruikt en uitgevoerd door een apparaat, programma of systeem. Gegevens worden verzonden naar en opgeslagen in het geheugen of andere vluchtige opslag totdat het programma of de computer hierom vraagt.
SPOOL is een acroniem voor gelijktijdige randactiviteiten online . Over het algemeen wordt de spoel onderhouden in het fysieke geheugen van de computer, in de buffers of in de I/O-apparaatspecifieke interrupts. De spoel wordt in oplopende volgorde verwerkt en werkt op basis van een FIFO-algoritme (first-in, first-out).
Spoolen verwijst naar het in een buffer plaatsen van gegevens van verschillende I/O-taken. Deze buffer is een speciaal gebied in het geheugen of de harde schijf dat toegankelijk is voor I/O-apparaten. Een besturingssysteem voert de volgende activiteiten uit met betrekking tot de gedistribueerde omgeving:
- Verwerkt de gegevensspooling van I/O-apparaten, aangezien apparaten verschillende gegevenstoegangssnelheden hebben.
- Onderhoudt de spoolingbuffer, die een wachtstation biedt waar gegevens kunnen rusten terwijl het langzamere apparaat de achterstand inhaalt.
- Handhaaft parallelle berekeningen vanwege het spoolingproces, aangezien een computer I/O in parallelle volgorde kan uitvoeren. Het wordt mogelijk om de computer gegevens van een tape te laten lezen, gegevens naar schijf te schrijven en naar een tapeprinter te laten schrijven terwijl deze zijn computertaak uitvoert.
Hoe spoolen werkt in het besturingssysteem
In een besturingssysteem werkt spoolen in de volgende stappen, zoals:
- Bij spoolen wordt een buffer aangemaakt met de naam SPOOL, die wordt gebruikt om taken en gegevens tegen te houden totdat het apparaat waarin de SPOOL is gemaakt klaar is om die taak te gebruiken en uit te voeren of om met de gegevens te werken.
- Wanneer een sneller apparaat gegevens naar een langzamer apparaat verzendt om een bepaalde bewerking uit te voeren, gebruikt het elk secundair geheugen dat is aangesloten als SPOOL-buffer. Deze gegevens worden in de SPOOL bewaard totdat het langzamere apparaat klaar is om met deze gegevens te werken. Wanneer het langzamere apparaat gereed is, worden de gegevens in de SPOOL in het hoofdgeheugen geladen voor de vereiste bewerkingen.
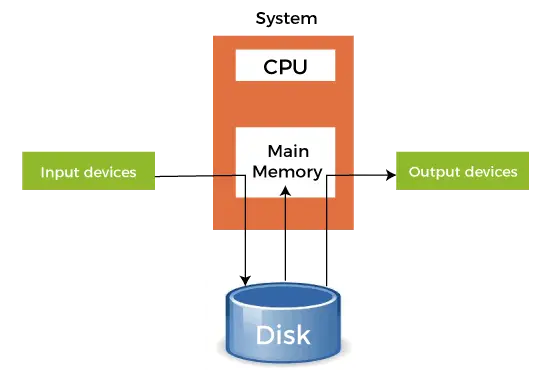
- Spooling beschouwt het volledige secundaire geheugen als een enorme buffer die veel taken en gegevens voor veel bewerkingen kan opslaan. Het voordeel van spoolen is dat het een wachtrij met taken kan creëren die in FIFO-volgorde worden uitgevoerd, zodat de taken één voor één kunnen worden uitgevoerd.
- Een apparaat kan verbinding maken met veel invoerapparaten, waarvoor mogelijk enige bewerking van de gegevens nodig is. Al deze invoerapparaten kunnen dus hun gegevens in het secundaire geheugen (SPOOL) plaatsen, dat vervolgens één voor één door het apparaat kan worden uitgevoerd. Dit zorgt ervoor dat de CPU op geen enkel moment inactief is. We kunnen dus zeggen dat spoolen een combinatie is van bufferen en in de wachtrij plaatsen.
- Nadat de CPU enige uitvoer heeft gegenereerd, wordt deze uitvoer eerst in het hoofdgeheugen opgeslagen. Deze uitvoer wordt vanuit het hoofdgeheugen overgebracht naar het secundaire geheugen en van daaruit wordt de uitvoer naar de respectieve uitvoerapparaten gestuurd.

Voorbeeld van spoelen
Het grootste voorbeeld van spoolen is afdrukken . De documenten die moeten worden afgedrukt, worden opgeslagen in de SPOOL en vervolgens toegevoegd aan de wachtrij voor afdrukken. Gedurende deze tijd kunnen veel processen hun werkzaamheden uitvoeren en de CPU gebruiken zonder te wachten terwijl de printer het afdrukproces op de documenten één voor één uitvoert.

Er kunnen ook veel functies aan het afdrukproces in de wachtrij worden toegevoegd, zoals het instellen van prioriteiten of een melding wanneer het afdrukproces is voltooid of het selecteren van de verschillende soorten papier waarop moet worden afgedrukt, afhankelijk van de keuze van de gebruiker.
Voordelen van spoelen
Hier volgen de volgende voordelen van spoolen in een besturingssysteem, zoals:
Hoeveel Mission Impossible-films zijn er?
- Het aantal I/O-apparaten of bewerkingen doet er niet toe. Veel I/O-apparaten kunnen gelijktijdig samenwerken zonder enige interferentie of verstoring van elkaar.
- Bij spoolen is er geen interactie tussen de I/O-apparaten en de CPU. Dat betekent dat de CPU niet hoeft te wachten tot de I/O-bewerkingen plaatsvinden. Het duurt lang voordat dergelijke bewerkingen zijn uitgevoerd, dus de CPU wacht niet tot ze zijn voltooid.
- CPU in de inactieve toestand wordt niet als zeer efficiënt beschouwd. De meeste protocollen zijn gemaakt om de CPU efficiënt te gebruiken in een minimale hoeveelheid tijd. Bij het spoolen blijft de CPU het grootste deel van de tijd bezig en gaat pas naar de inactieve toestand als de wachtrij leeg is. Alle taken worden dus aan de wachtrij toegevoegd en de CPU voltooit al deze taken en gaat vervolgens naar de inactieve status.
- Het zorgt ervoor dat applicaties op de snelheid van de CPU kunnen draaien terwijl de I/O-apparaten op hun respectieve volledige snelheid werken.
Nadelen van spoelen
In een besturingssysteem heeft spoolen de volgende nadelen, zoals:
- Voor spoolen is een grote hoeveelheid opslagruimte nodig, afhankelijk van het aantal verzoeken dat door de invoer wordt gedaan en het aantal aangesloten invoerapparaten.
- Omdat de SPOOL in de secundaire opslag wordt gemaakt, kan het hebben van veel invoerapparaten die tegelijkertijd werken veel ruimte in beslag nemen op de secundaire opslag, waardoor het schijfverkeer toeneemt. Dit heeft tot gevolg dat de schijf steeds langzamer wordt naarmate het verkeer steeds groter wordt.
- Spoolen wordt gebruikt voor het kopiëren en uitvoeren van gegevens van een langzamer apparaat naar een sneller apparaat. Het langzamere apparaat creëert een SPOOL om de te bewerken gegevens in een wachtrij op te slaan, en de CPU werkt eraan. Dit proces op zichzelf maakt spoolen nutteloos om te gebruiken in realtime-omgevingen waar we realtime resultaten van de CPU nodig hebben. Dit komt omdat het invoerapparaat langzamer is en dus zijn gegevens in een langzamer tempo produceert, terwijl de CPU sneller kan werken, zodat deze doorgaat naar het volgende proces in de wachtrij. Daarom wordt het eindresultaat of de output op een later tijdstip geproduceerd in plaats van in realtime.
Verschil tussen spoolen en bufferen
Spoolen en bufferen zijn de twee manieren waarop I/O-subsystemen de prestaties en efficiëntie van de computer verbeteren door gebruik te maken van opslagruimte in het hoofdgeheugen of op de schijf.

Het fundamentele verschil tussen spoolen en bufferen is dat spoolen de I/O van de ene taak overlapt met de uitvoering van een andere taak. Ter vergelijking: de buffering overlapt de I/O van één taak met de uitvoering van dezelfde taak. Hieronder staan nog enkele verschillen tussen spoolen en bufferen, zoals:
| Voorwaarden | Opspoelen | Bufferen |
|---|---|---|
| Definitie | Spooling, een acroniem van Simultaneous Peripheral Operation Online (SPOOL), plaatst gegevens in een tijdelijk werkgebied waar ze kunnen worden geopend en verwerkt door een ander programma of een andere bron. | Bufferen is het tijdelijk opslaan van gegevens in de buffer. Het helpt bij het afstemmen van de snelheid van de datastroom tussen de zender en de ontvanger. |
| Vereiste middelen | Voor spoolen is minder resourcebeheer nodig, omdat verschillende resources het proces voor specifieke taken beheren. | Buffering vereist meer resourcebeheer omdat dezelfde resource het proces van dezelfde verdeelde taak beheert. |
| Interne implementatie | Bij spoolen wordt de invoer en uitvoer van één taak overlapt met de berekening van een andere taak. | Buffering overlapt de invoer en uitvoer van één taak met de berekening van dezelfde taak. |
| Efficiënt | Spoolen is efficiënter dan bufferen. | Bufferen is minder efficiënt dan spoolen. |
| Verwerker | Met spoolen kunnen ook gegevens op externe locaties worden verwerkt. De spooler hoeft alleen maar te melden wanneer een proces op de externe locatie is voltooid om het volgende proces naar het externe apparaat te spoolen. | Buffering ondersteunt geen verwerking op afstand. |
| Grootte op geheugen | Het beschouwt de schijf als een enorme spoel of buffer. | Buffer is een beperkt gebied in het hoofdgeheugen. |