In de vorige sectie hebben we een korte introductie gegeven over Apache Kafka, het berichtensysteem en het streamingproces. Hier bespreken we de basisconcepten en de rol van Kafka.
Onderwerpen
Over het algemeen verwijst een onderwerp naar een bepaalde kop of een naam die wordt gegeven aan een aantal specifieke onderling gerelateerde ideeën. In Kafka verwijst het woord onderwerp naar een categorie of een algemene naam die wordt gebruikt om een bepaalde gegevensstroom op te slaan en te publiceren. In principe zijn onderwerpen in Kafka vergelijkbaar met tabellen in de database, maar bevatten ze niet alle beperkingen. In Kafka kunnen we een aantal onderwerpen maken zoals we willen. Het wordt geïdentificeerd door zijn naam, die afhangt van de keuze van de gebruiker. Een producent publiceert gegevens over de onderwerpen, en een consument leest die gegevens uit het onderwerp door zich erop te abonneren.
Partities
Een onderwerp is opgesplitst in verschillende delen die bekend staan als de partities van het onderwerp. Deze partities zijn in een volgorde gescheiden. De gegevensinhoud wordt opgeslagen in de partities binnen het onderwerp. Daarom moeten we bij het maken van een onderwerp het aantal partities opgeven (het aantal is willekeurig en kan later worden gewijzigd). Elk bericht wordt opgeslagen in partities met een incrementele ID die bekend staat als de Offset-waarde. De volgorde van de offsetwaarde is alleen binnen de partitie gegarandeerd en niet over de partitie heen. De offsets voor een partitie zijn oneindig.
Opmerking:De gegevens die eenmaal naar een partitie zijn geschreven, kunnen nooit meer worden gewijzigd. Het is onveranderlijk. De offsetwaarde blijft altijd incrementeel en gaat nooit terug naar een lege ruimte. Bovendien worden de gegevens slechts een beperkte tijd op een partitie bewaard.
Laten we een voorbeeld bekijken om een onderwerp met zijn partities te begrijpen.
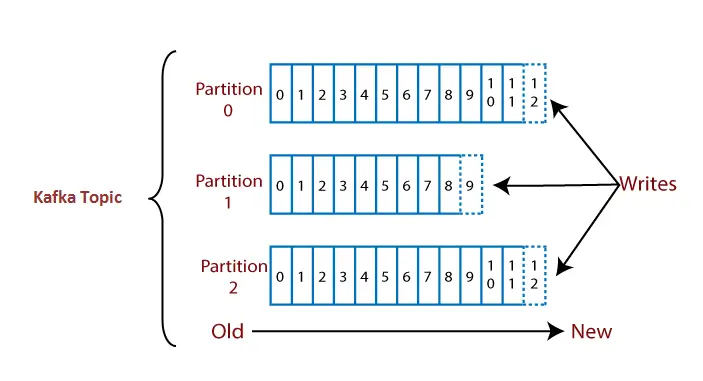
Stel dat een onderwerp drie partities 0,1 en 2 bevat. Elke partitie heeft verschillende offsetnummers. De gegevens worden verdeeld over elke offset in elke partitie waar gegevens in offset 1 van partitie 0 geen enkele relatie hebben met de gegevens in offset 1 van partitie 1. Maar de gegevens in offset 1 van partitie 0 zijn onderling gerelateerd aan de gegevens in offset 2 van partitie 0.
Makelaars
Hier komt de rol van Apache Kafka.
Een Kafka-cluster bestaat uit een of meer servers die bekend staan als makelaars of Kafka-makelaars. Een makelaar is een container die verschillende onderwerpen met hun meerdere partities bevat. De makelaars in het cluster worden alleen geïdentificeerd door een geheel getal-ID. Kafka-makelaars worden ook wel genoemd Bootstrap-makelaars omdat verbinding met één makelaar verbinding met het hele cluster betekent. Hoewel een makelaar geen volledige gegevens bevat, is elke makelaar in het cluster op de hoogte van alle andere makelaars, partities en onderwerpen.

Zo ziet een makelaar eruit in de figuur met een onderwerp met n aantal partities.
Voorbeeld: makelaars en onderwerpen
Stel een Kafka-cluster bestaande uit drie makelaars, namelijk Broker 1, Broker 2 en Broker 3.

Elke makelaar heeft een topic, namelijk Topic-x met drie partities 0,1 en 2. Onthoud dat alle partities niet aan slechts één makelaar toebehoren, deze wordt altijd onder elke makelaar verdeeld (afhankelijk van de hoeveelheid). Broker 1 en Broker 2 bevatten nog een topic-y met twee partities 0 en 1. Broker 3 bevat dus geen gegevens van Topic-y. Ook wordt geconcludeerd dat er nooit een relatie bestaat tussen het makelaarsnummer en het partitienummer.