In de volgende architectuur wordt de stroom van het indienen van query's in Hive uitgelegd.
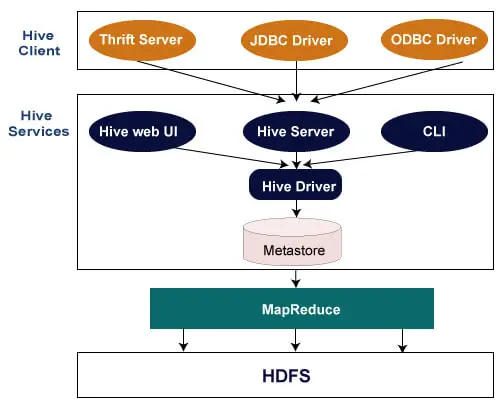
Hive-klant
Hive maakt het schrijven van applicaties in verschillende talen mogelijk, waaronder Java, Python en C++. Het ondersteunt verschillende soorten klanten, zoals: -
- Thrift Server - Het is een meertalig serviceproviderplatform dat de verzoeken van alle programmeertalen die Thrift ondersteunen, verwerkt.
- JDBC-stuurprogramma - Het wordt gebruikt om een verbinding tot stand te brengen tussen hive- en Java-applicaties. Het JDBC-stuurprogramma is aanwezig in de klasse org.apache.hadoop.hive.jdbc.HiveDriver.
- ODBC-stuurprogramma - Hiermee kunnen toepassingen die het ODBC-protocol ondersteunen verbinding maken met Hive.
Hive-diensten
Dit zijn de diensten die door Hive worden geleverd: -
- Hive CLI - De Hive CLI (Command Line Interface) is een shell waarin we Hive-query's en -opdrachten kunnen uitvoeren.
- Hive-webgebruikersinterface - De Hive-webgebruikersinterface is slechts een alternatief voor Hive CLI. Het biedt een webgebaseerde GUI voor het uitvoeren van Hive-query's en -opdrachten.
- Hive MetaStore - Het is een centrale opslagplaats die alle structuurinformatie van verschillende tabellen en partities in het magazijn opslaat. Het bevat ook metagegevens van de kolom en de type-informatie, de serializers en deserializers die worden gebruikt om gegevens te lezen en te schrijven en de bijbehorende HDFS-bestanden waarin de gegevens zijn opgeslagen.
- Hive Server - Het wordt Apache Thrift Server genoemd. Het accepteert het verzoek van verschillende clients en geeft het door aan Hive Driver.
- Hive-stuurprogramma - Het ontvangt vragen van verschillende bronnen, zoals web-UI, CLI, Thrift en JDBC/ODBC-stuurprogramma. Het verzendt de vragen naar de compiler.
- Hive Compiler - Het doel van de compiler is om de query te ontleden en semantische analyses uit te voeren op de verschillende queryblokken en expressies. Het converteert HiveQL-instructies naar MapReduce-taken.
- Hive Execution Engine - Optimizer genereert het logische plan in de vorm van DAG van kaartverkleinende taken en HDFS-taken. Uiteindelijk voert de uitvoeringsengine de binnenkomende taken uit in de volgorde van hun afhankelijkheden.