Voordat we naar de verschillen tussen BFS en DFS kijken, moeten we eerst afzonderlijk over BFS en DFS weten.
Wat is BFS?
BFS betekent Breedte eerste zoekopdracht . Het is ook bekend als niveauvolgorde doorlopen . De wachtrijgegevensstructuur wordt gebruikt voor het doorlopen van de breedte-eerste zoekopdracht. Wanneer we het BFS-algoritme gebruiken voor het doorlopen van een grafiek, kunnen we elk knooppunt als een hoofdknooppunt beschouwen.
Laten we de onderstaande grafiek bekijken voor de breedte van de eerste zoekopdracht.
Java-uitzonderingen
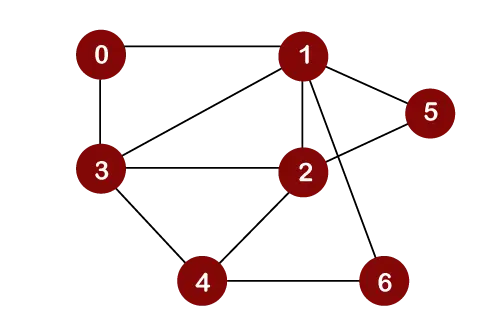
Stel dat we knooppunt 0 als een hoofdknooppunt beschouwen. Daarom zou de doortocht worden gestart vanaf knooppunt 0.

Zodra knooppunt 0 uit de wachtrij is verwijderd, wordt het afgedrukt en gemarkeerd als een bezocht knooppunt.
Zodra knooppunt 0 uit de wachtrij wordt verwijderd, worden de aangrenzende knooppunten van knooppunt 0 in een wachtrij ingevoegd, zoals hieronder weergegeven:

Nu wordt knooppunt 1 uit de wachtrij verwijderd; het wordt afgedrukt en gemarkeerd als een bezocht knooppunt
Zodra knooppunt 1 uit de wachtrij wordt verwijderd, worden alle aangrenzende knooppunten van knooppunt 1 aan een wachtrij toegevoegd. De aangrenzende knooppunten van knooppunt 1 zijn 0, 3, 2, 6 en 5. Maar we moeten alleen niet-bezochte knooppunten in een wachtrij invoegen. Omdat knooppunten 3, 2, 6 en 5 niet bezocht zijn; daarom worden deze knooppunten toegevoegd aan een wachtrij, zoals hieronder weergegeven:

Het volgende knooppunt is 3 in een wachtrij. Knooppunt 3 wordt dus uit de wachtrij verwijderd, het wordt afgedrukt en gemarkeerd als bezocht, zoals hieronder weergegeven:

Zodra knooppunt 3 uit de wachtrij wordt verwijderd, worden alle aangrenzende knooppunten van knooppunt 3, behalve de bezochte knooppunten, aan een wachtrij toegevoegd. De aangrenzende knooppunten van knooppunt 3 zijn 0, 1, 2 en 4. Omdat knooppunten 0, 1 al zijn bezocht en knooppunt 2 aanwezig is in een wachtrij; daarom hoeven we alleen knooppunt 4 in een wachtrij in te voegen.
lijst versus set in Java

Het volgende knooppunt in de wachtrij is nu 2. Er wordt dus 2 uit de wachtrij verwijderd. Het wordt afgedrukt en gemarkeerd als bezocht, zoals hieronder weergegeven:

Zodra knooppunt 2 uit de wachtrij wordt verwijderd, worden alle aangrenzende knooppunten van knooppunt 2, behalve de bezochte knooppunten, aan een wachtrij toegevoegd. De aangrenzende knooppunten van knooppunt 2 zijn 1, 3, 5, 6 en 4. Omdat de knooppunten 1 en 3 al zijn bezocht en 4, 5, 6 al aan de wachtrij zijn toegevoegd; daarom hoeven we geen enkel knooppunt in de wachtrij in te voegen.
Het volgende element is 5. Dus 5 zou uit de wachtrij worden verwijderd. Het wordt afgedrukt en gemarkeerd als bezocht, zoals hieronder weergegeven:

Zodra knooppunt 5 uit de wachtrij wordt verwijderd, worden alle aangrenzende knooppunten van knooppunt 5, behalve de bezochte knooppunten, aan de wachtrij toegevoegd. De aangrenzende knooppunten van knooppunt 5 zijn 1 en 2. Aangezien beide knooppunten al zijn bezocht; daarom is er geen hoekpunt dat in een wachtrij kan worden ingevoegd.
Het volgende knooppunt is 6. Dus 6 zou uit de wachtrij worden verwijderd. Het wordt afgedrukt en gemarkeerd als bezocht, zoals hieronder weergegeven:

Zodra knooppunt 6 uit de wachtrij wordt verwijderd, worden alle aangrenzende knooppunten van knooppunt 6, behalve de bezochte knooppunten, aan de wachtrij toegevoegd. De aangrenzende knooppunten van knooppunt 6 zijn 1 en 4. Aangezien knooppunt 1 al is bezocht en knooppunt 4 al aan de wachtrij is toegevoegd; daarom is er geen hoekpunt dat in de wachtrij moet worden ingevoegd.
Het volgende element in de wachtrij is 4. 4 wordt dus uit de wachtrij verwijderd. Het wordt afgedrukt en gemarkeerd als bezocht.
Zodra knooppunt 4 uit de wachtrij wordt verwijderd, worden alle aangrenzende knooppunten van knooppunt 4, behalve de bezochte knooppunten, aan de wachtrij toegevoegd. De aangrenzende knooppunten van knooppunt 4 zijn 3, 2 en 6. Omdat alle aangrenzende knooppunten al zijn bezocht; er hoeft dus geen hoekpunt in de wachtrij te worden ingevoegd.
Wat is DFS?
DFS staat voor Depth First Search. Bij DFS-traversal wordt de stapeldatastructuur gebruikt, die werkt volgens het LIFO-principe (Last In First Out). In DFS kan het doorlopen vanaf elk knooppunt worden gestart, of we kunnen zeggen dat elk knooppunt als een hoofdknooppunt kan worden beschouwd totdat het hoofdknooppunt niet in het probleem wordt genoemd.
np.random.rand
In het geval van BFS, het element dat uit de wachtrij wordt verwijderd, worden de aangrenzende knooppunten van het verwijderde knooppunt aan de wachtrij toegevoegd. In DFS daarentegen wordt het element dat uit de stapel wordt verwijderd, slechts één aangrenzend knooppunt van een verwijderd knooppunt aan de stapel toegevoegd.
Laten we de onderstaande grafiek bekijken voor de diepte-eerste-zoektocht.

Beschouw knooppunt 0 als een hoofdknooppunt.
Eerst plaatsen we element 0 in de stapel, zoals hieronder weergegeven:

Knooppunt 0 heeft twee aangrenzende knooppunten, d.w.z. 1 en 3. Nu kunnen we slechts één aangrenzend knooppunt, 1 of 3, gebruiken om te doorlopen. Stel dat we knooppunt 1 beschouwen; daarom wordt 1 in een stapel geplaatst en afgedrukt zoals hieronder weergegeven:

Nu gaan we kijken naar de aangrenzende hoekpunten van knooppunt 1. De niet bezochte aangrenzende hoekpunten van knooppunt 1 zijn 3, 2, 5 en 6. We kunnen elk van deze vier hoekpunten beschouwen. Stel dat we knooppunt 3 nemen en in de stapel plaatsen, zoals hieronder weergegeven:
vba

Beschouw de niet-bezochte aangrenzende hoekpunten van knooppunt 3. De niet-bezochte aangrenzende hoekpunten van knooppunt 3 zijn 2 en 4. We kunnen een van de hoekpunten nemen, dat wil zeggen 2 of 4. Stel dat we hoekpunt 2 nemen en dit in de stapel plaatsen, zoals hieronder weergegeven:

De niet-bezochte aangrenzende hoekpunten van knooppunt 2 zijn 5 en 4. We kunnen een van de hoekpunten kiezen, dat wil zeggen 5 of 4. Stel dat we hoekpunt 4 nemen en in de stapel invoegen, zoals hieronder weergegeven:

Nu zullen we de niet-bezochte aangrenzende hoekpunten van knooppunt 4 beschouwen. Het niet-bezochte aangrenzende hoekpunt van knooppunt 4 is knooppunt 6. Daarom wordt element 6 in de stapel ingevoegd, zoals hieronder weergegeven:

Nadat we element 6 in de stapel hebben geplaatst, kijken we naar de niet-bezochte aangrenzende hoekpunten van knooppunt 6. Omdat er geen onbezochte aangrenzende hoekpunten van knooppunt 6 zijn, kunnen we niet verder gaan dan knooppunt 6. In dit geval zullen we uitvoeren terugtrekken . Het bovenste element, d.w.z. 6, wordt uit de stapel gehaald, zoals hieronder weergegeven:


Het bovenste element in de stapel is 4. Omdat er geen onbezochte aangrenzende hoekpunten over zijn van knooppunt 4; daarom wordt knooppunt 4 uit de stapel gehaald, zoals hieronder weergegeven:


Het volgende bovenste element in de stapel is 2. Nu zullen we kijken naar de niet-bezochte aangrenzende hoekpunten van knooppunt 2. Omdat er nog maar één niet-bezocht knooppunt, d.w.z. 5, over is, wordt knooppunt 5 in de stapel boven 2 geduwd en afgedrukt. zoals hieronder weergegeven:
in Java-regex

Nu gaan we de aangrenzende hoekpunten van knooppunt 5 controleren, die nog niet bezocht zijn. Omdat er geen hoekpunt meer is om te bezoeken, halen we element 5 van de stapel, zoals hieronder weergegeven:

We kunnen niet verder gaan dan 5, dus we moeten teruggaan. Bij backtracking zou het bovenste element uit de stapel springen. Het bovenste element is 5 dat uit de stapel zou worden gehaald, en we gaan terug naar knooppunt 2, zoals hieronder weergegeven:

Nu zullen we de niet-bezochte aangrenzende hoekpunten van knooppunt 2 controleren. Omdat er geen aangrenzend hoekpunt meer is om te bezoeken, voeren we backtracking uit. Bij backtracking wordt het bovenste element, d.w.z. 2, uit de stapel gehaald en gaan we terug naar knooppunt 3, zoals hieronder weergegeven:


Nu zullen we de niet-bezochte aangrenzende hoekpunten van knooppunt 3 controleren. Omdat er geen aangrenzend hoekpunt meer is om te bezoeken, voeren we backtracking uit. Bij backtracking wordt het bovenste element, d.w.z. 3, uit de stapel gehaald en gaan we terug naar knooppunt 1, zoals hieronder weergegeven:


Nadat we element 3 eruit hebben gehaald, zullen we de niet-bezochte aangrenzende hoekpunten van knooppunt 1 controleren. Omdat er geen hoekpunt meer is om te bezoeken; daarom zal de backtracking worden uitgevoerd. Bij backtracking wordt het bovenste element, d.w.z. 1, uit de stapel gehaald en gaan we terug naar knooppunt 0, zoals hieronder weergegeven:


We zullen de aangrenzende hoekpunten van knooppunt 0 controleren, die nog niet zijn bezocht. Omdat er geen aangrenzend hoekpunt meer te bezoeken is, voeren we backtracking uit. Hierin zou slechts één element, d.w.z. 0 overgebleven in de stapel, uit de stapel worden gehaald, zoals hieronder weergegeven:

Zoals we in de bovenstaande figuur kunnen zien, is de stapel leeg. We moeten dus de DFS-beweging hier stoppen, en de elementen die worden afgedrukt zijn het resultaat van de DFS-beweging.
Verschillen tussen BFS en DFS
Hieronder volgen de verschillen tussen de BFS en DFS:
| BFS | DFS | |
|---|---|---|
| Volledige vorm | BFS staat voor Breadth First Search. | DFS staat voor Depth First Search. |
| Techniek | Het is een op hoekpunten gebaseerde techniek om het kortste pad in een grafiek te vinden. | Het is een randgebaseerde techniek omdat de hoekpunten langs de rand eerst worden verkend, van het begin- tot het eindknooppunt. |
| Definitie | BFS is een traversal-techniek waarbij eerst alle knooppunten van hetzelfde niveau worden verkend, waarna we naar het volgende niveau gaan. | DFS is ook een traversal-techniek waarbij de traversal wordt gestart vanaf het hoofdknooppunt en de knooppunten zo ver mogelijk verkennen totdat we het knooppunt bereiken dat geen onbezochte aangrenzende knooppunten heeft. |
| Data structuur | De wachtrijgegevensstructuur wordt gebruikt voor de BFS-traversal. | Voor de BFS-traversal wordt een stapeldatastructuur gebruikt. |
| Terugkeren | BFS maakt geen gebruik van het backtracking-concept. | DFS gebruikt backtracking om alle niet-bezochte knooppunten te doorkruisen. |
| Aantal randen | BFS vindt het kortste pad met een minimum aantal randen dat moet worden afgelegd van het bron- naar het bestemmingspunt. | In DFS is een groter aantal randen vereist om van het bronpunt naar het doelpunt te gaan. |
| Optimaliteit | BFS-traversal is optimaal voor die hoekpunten die dichter bij het bronpunt moeten worden doorzocht. | DFS-traversal is optimaal voor die grafieken waarin oplossingen zich niet in de buurt van het bronpunt bevinden. |
| Snelheid | BFS is langzamer dan DFS. | DFS is sneller dan BFS. |
| Geschiktheid voor beslisboom | Het is niet geschikt voor de beslissingsboom, omdat hiervoor eerst alle aangrenzende knooppunten moeten worden onderzocht. | Het is geschikt voor de beslisboom. Op basis van de beslissing verkent het alle paden. Wanneer het doel is gevonden, stopt het zijn verplaatsing. |
| Geheugen efficiënt | Het is niet geheugenefficiënt omdat het meer geheugen vereist dan DFS. | Het is geheugenefficiënt omdat het minder geheugen vereist dan BFS. |