Voordat we iets weten over het abstracte gegevenstype, moeten we weten wat een gegevensstructuur is.
Wat is datastructuur?
Een datastructuur is een techniek om de gegevens zo te organiseren dat de gegevens efficiënt kunnen worden gebruikt. Er zijn twee manieren om de gegevensstructuur te bekijken:
Waarom datastructuur?
Dit zijn de voordelen van het gebruik van de datastructuur:
- Dit zijn de essentiële ingrediënten die worden gebruikt voor het creëren van snelle en krachtige algoritmen.
- Ze helpen ons de gegevens te beheren en te ordenen.
- Datastructuren maken de code schoner en gemakkelijker te begrijpen.
Wat is een abstract gegevenstype?
Een abstract datatype is een abstractie van een datastructuur die alleen de interface biedt waaraan de datastructuur moet voldoen. De interface geeft geen specifieke details over iets dat geïmplementeerd moet worden of in welke programmeertaal.
Met andere woorden, we kunnen zeggen dat abstracte gegevenstypen de entiteiten zijn die definities van gegevens en bewerkingen zijn, maar geen implementatiedetails hebben. In dit geval kennen we de gegevens die we opslaan en de bewerkingen die op de gegevens kunnen worden uitgevoerd, maar we weten niets van de implementatiedetails. De reden dat er geen implementatiedetails beschikbaar zijn, is dat elke programmeertaal bijvoorbeeld een andere implementatiestrategie heeft; een C-datastructuur wordt geïmplementeerd met behulp van structuren, terwijl een C++-datastructuur wordt geïmplementeerd met behulp van objecten en klassen.
Bijvoorbeeld, een lijst is een abstract gegevenstype dat wordt geïmplementeerd met behulp van een dynamische array en een gekoppelde lijst. Er wordt een wachtrij geïmplementeerd met behulp van een gekoppelde, op een lijst gebaseerde wachtrij, een op een array gebaseerde wachtrij en een op een stapel gebaseerde wachtrij. Een kaart wordt geïmplementeerd met behulp van een boomkaart, hashkaart of hashtabel.
Abstract gegevenstypemodel
Voordat we iets weten over het abstracte gegevenstypemodel, moeten we iets weten over abstractie en inkapseling.
Java-tutorial voor beginners
Abstractie: Het is een techniek om de interne gegevens voor de gebruiker te verbergen en alleen de noodzakelijke details aan de gebruiker te tonen.
Inkapseling: Het is een techniek waarbij de gegevens en de lidfunctie in één enkele eenheid worden gecombineerd en staat bekend als inkapseling.
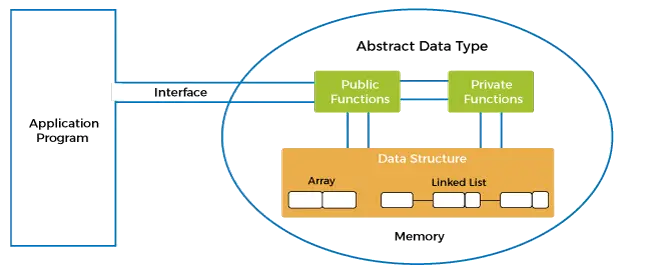
De bovenstaande figuur toont het ADT-model. Er zijn twee soorten modellen in het ADT-model, namelijk de publieke functie en de private functie. Het ADT-model bevat ook de datastructuren die we in een programma gebruiken. In dit model wordt de eerste inkapseling uitgevoerd, d.w.z. alle gegevens worden verpakt in een enkele eenheid, d.w.z. ADT. Vervolgens wordt de abstractie uitgevoerd, waarbij de bewerkingen worden getoond die op de datastructuur kunnen worden uitgevoerd en wat de datastructuren zijn die we in een programma gebruiken.
Laten we het abstracte gegevenstype begrijpen met een voorbeeld uit de praktijk.
Als we kijken naar de smartphone. We kijken naar de hoge specificaties van de smartphone, zoals:
- 4 GB RAM
- Snapdragon-processor van 2,2 GHz
- 5 inch LCD-scherm
- Tweevoudige camera
- Android 8.0
Bovenstaande specificaties van de smartphone zijn de gegevens, daarnaast kunnen we op de smartphone de volgende handelingen uitvoeren:
De smartphone is een entiteit waarvan de gegevens of specificaties en bewerkingen hierboven worden gegeven. De abstract/logische weergave en bewerkingen zijn de abstracte of logische weergaven van een smartphone.
De implementatieweergave van de bovenstaande abstracte/logische weergave wordt hieronder gegeven:
class Smartphone { private: int ramSize; string processorName; float screenSize; int cameraCount; string androidVersion; public: void call(); void text(); void photo(); void video(); } De bovenstaande code is de implementatie van de specificaties en bewerkingen die op de smartphone kunnen worden uitgevoerd. De implementatievisie kan verschillen omdat de syntaxis van programmeertalen anders is, maar de abstracte/logische weergave van de datastructuur zou hetzelfde blijven. Daarom kunnen we zeggen dat de abstracte/logische visie onafhankelijk is van de implementatievisie.
Opmerking: we kennen de bewerkingen die kunnen worden uitgevoerd op de vooraf gedefinieerde gegevenstypen zoals int, float, char, enz., maar we kennen de implementatiedetails van de gegevenstypen niet. Daarom kunnen we zeggen dat het abstracte gegevenstype wordt beschouwd als het verborgen vak dat alle interne details van het gegevenstype verbergt.
Voorbeeld van datastructuur
Stel dat we een indexarray van grootte 4 hebben. We hebben een indexlocatie die begint bij 0, 1, 2, 3. Array is een gegevensstructuur waarbij de elementen op een aaneengesloten locatie worden opgeslagen. Het geheugenadres van het eerste element is 1000, het tweede element is 1004, het derde element is 1008 en het vierde element is 1012. Omdat het van het integer-type is, zal het 4 bytes in beslag nemen en is het verschil tussen de adressen van elk element 4 bytes. De waarden die in een array zijn opgeslagen zijn 10, 20, 30 en 40. Deze waarden, indexposities en de geheugenadressen zijn de implementaties.
De abstracte of logische weergave van de integer-array kan als volgt worden uitgedrukt:
- Het slaat een reeks elementen van het integer-type op.
- Het leest de elementen op positie, d.w.z. index.
- Het wijzigt de elementen per index
- Het voert sortering uit
De implementatieweergave van de integer-array:
verander de naam directory linux
a[4] = {10, 20, 30, 40} cout<< a[2] a[3] = 50