Excel-sheets zijn zeer instinctief en gebruiksvriendelijk, waardoor ze ideaal zijn voor het manipuleren van grote datasets, zelfs voor minder technische mensen. Als u op zoek bent naar plaatsen waar u dingen in Excel-bestanden kunt manipuleren en automatiseren met behulp van Python , zoek niet verder. U bent op de juiste plaats.
In dit artikel leert u hoe u dit kunt gebruiken Panda's werken met Excel-spreadsheets. In dit artikel zullen we leren over:
- Lezen Excel bestand Panda's gebruiken in Python
- Panda's installeren en importeren
- Meerdere Excel-sheets lezen met Pandas
- Toepassing van verschillende Pandas-functies
Excel-bestand lezen met Panda's in Python
Panda's installeren
Om Pandas in Python te installeren, kunnen we de volgende opdracht in de opdrachtprompt gebruiken:
pip install pandas>
Om Panda's in Anaconda te installeren, kunnen we de volgende opdracht in Anaconda Terminal gebruiken:
conda install pandas>
Panda's importeren
Allereerst moeten we de Pandas-module importeren, wat gedaan kan worden door de opdracht uit te voeren:
Python3
import> pandas as pd> |
>
>
Invoer bestand: Laten we aannemen dat het Excel-bestand er zo uitziet
Blad 1:

Blad 1
Blad 2:
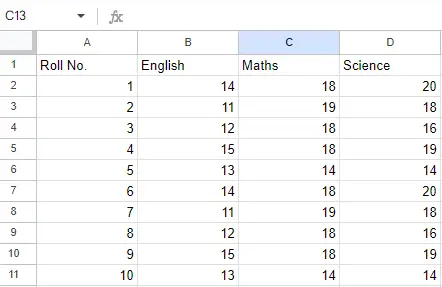
Blad 2
Nu kunnen we het Excel-bestand importeren met behulp van de read_excel-functie in Pandas om het Excel-bestand te lezen met Pandas in Python. De tweede instructie leest de gegevens uit Excel en slaat deze op in een Panda Data Frame dat wordt weergegeven door de variabele newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Uitgang:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Meerdere bladen laden met de Concat()-methode
Als de Excel-werkmap meerdere werkbladen bevat, importeert de opdracht gegevens uit het eerste werkblad. Als u een gegevensframe wilt maken met alle werkbladen in de werkmap, is de eenvoudigste methode het afzonderlijk maken van verschillende gegevensframes en deze vervolgens samenvoegen. De read_excel-methode gebruikt het argument sheet_name en index_col, waar we het blad kunnen specificeren waaruit het frame moet bestaan, en index_col specificeert de titelkolom, zoals hieronder wordt weergegeven:
Voorbeeld:
De derde verklaring voegt beide bladen samen. Om nu het hele dataframe te controleren, kunnen we eenvoudigweg de volgende opdracht uitvoeren:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Uitgang:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
De methoden Head() en Tail() in Panda's
Om 5 kolommen van boven en van onderen van het dataframe te bekijken, kunnen we de opdracht uitvoeren. Dit hoofd() En staart() methode neemt ook argumenten als getallen voor het aantal kolommen dat moet worden weergegeven.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Uitgang:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Vorm() methode
De vorm() methode kan worden gebruikt om het aantal rijen en kolommen in het dataframe als volgt te bekijken:
Python3
newData.shape> |
>
>
Uitgang:
(20, 3)>
Sort_values()-methode in Panda's
Als een kolom numerieke gegevens bevat, kunnen we die kolom sorteren met behulp van de sort_values() methode bij panda's als volgt:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Laten we nu aannemen dat we de top 5 waarden van de gesorteerde kolom willen, we kunnen hier de methode head() gebruiken:
Python3
sorted_column.head(>5>)> |
>
>
Uitgang:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
We kunnen dat doen met elke numerieke kolom van het dataframe, zoals hieronder weergegeven:
Python3
newData[>'Maths'>].head()> |
>
Java-interviewvragen
>
Uitgang:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Panda's Describe()-methode
Stel nu dat onze gegevens voornamelijk numeriek zijn. We kunnen de statistische informatie zoals gemiddelde, max, min, etc. over het dataframe verkrijgen met behulp van de beschrijven() methode zoals hieronder weergegeven:
Python3
newData.describe()> |
>
>
Uitgang:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Dit kan ook afzonderlijk worden gedaan voor alle numerieke kolommen met behulp van het volgende commando:
Python3
newData[>'English'>].mean()> |
>
>
Uitgang:
14.3>
Andere statistische informatie kan ook worden berekend met behulp van de respectieve methoden. Net als in Excel kunnen ook formules worden toegepast en kunnen berekende kolommen als volgt worden gemaakt:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Uitgang:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Nadat we de gegevens in het dataframe hebben bewerkt, kunnen we de gegevens terug exporteren naar een Excel-bestand met behulp van de methode to_excel. Hiervoor moeten we een Excel-uitvoerbestand opgeven waarin de getransformeerde gegevens moeten worden geschreven, zoals hieronder weergegeven:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Uitgang:
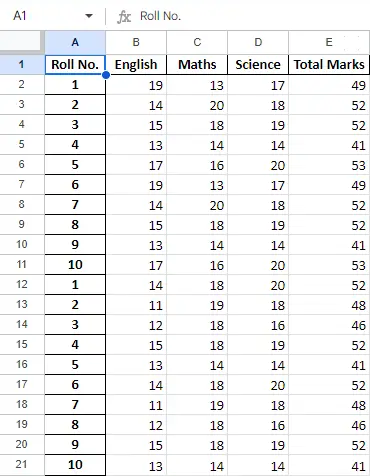
Laatste blad