Dierentuinmedewerker is een gedistribueerde, open-source coördinatieservice voor gedistribueerde applicaties. Het onthult een eenvoudige set primitieven om services op een hoger niveau te implementeren voor synchronisatie, configuratieonderhoud, en groep- en naamgeving.
In een gedistribueerd systeem zijn er meerdere knooppunten of machines die met elkaar moeten communiceren en hun acties moeten coördineren. ZooKeeper biedt een manier om ervoor te zorgen dat deze knooppunten zich van elkaar bewust zijn en hun acties kunnen coördineren. Het doet dit door een hiërarchische boom van dataknooppunten bij te houden Znodes , dat kan worden gebruikt voor het opslaan en ophalen van gegevens en het onderhouden van statusinformatie. ZooKeeper biedt een reeks primitieven, zoals sloten, barrières en wachtrijen, die kunnen worden gebruikt om de acties van knooppunten in een gedistribueerd systeem te coördineren. Het biedt ook functies zoals leiderverkiezing, failover en herstel, die ervoor kunnen zorgen dat het systeem bestand is tegen storingen. ZooKeeper wordt veel gebruikt in gedistribueerde systemen zoals Hadoop, Kafka en HBase, en is een essentieel onderdeel geworden van veel gedistribueerde applicaties.
Waarom hebben we het nodig?
- Coördinatiediensten : De integratie/communicatie van diensten in een gedistribueerde omgeving.
- Coördinatiediensten zijn lastig op de goede weg te krijgen. Ze zijn vooral gevoelig voor fouten, zoals raceomstandigheden en impasse.
- Race conditie -Twee of meer systemen die een bepaalde taak proberen uit te voeren.
- Impasses – Er wachten twee of meer operaties op elkaar.
- Om de coördinatie tussen gedistribueerde omgevingen eenvoudig te maken, kwamen ontwikkelaars met het idee zookeeper, zodat ze gedistribueerde applicaties niet hoeven te ontlasten van de verantwoordelijkheid om coördinatiediensten helemaal opnieuw te implementeren.
Wat is een gedistribueerd systeem?
- Meerdere computersystemen die aan één probleem werken.
- Het is een netwerk dat bestaat uit autonome computers die met elkaar zijn verbonden via gedistribueerde middleware.
- Belangrijkste kenmerken : Gelijktijdig, delen van bronnen, onafhankelijk, mondiaal, grotere fouttolerantie en prijs/prestatieverhouding is veel beter.
- Belangrijkste doel s: Transparantie, betrouwbaarheid, prestaties, schaalbaarheid.
- Uitdagingen : Beveiliging, Fouten, Coördinatie en het delen van bronnen.
Coördinatie-uitdaging
- Waarom is coördinatie in een gedistribueerd systeem het moeilijke probleem?
- Coördinatie- of configuratiebeheer voor een gedistribueerde applicatie met veel systemen.
- Master Node waar de clustergegevens worden opgeslagen.
- Werkknooppunten of slaafknooppunten halen de gegevens van dit masterknooppunt op.
- enig punt van falen.
- synchronisatie is niet eenvoudig.
- Een zorgvuldig ontwerp en implementatie zijn nodig.
Apache dierenverzorger
Apache Zookeeper is een gedistribueerde, open-source coördinatieservice voor gedistribueerde systemen. Het biedt een centrale plek voor gedistribueerde applicaties om gegevens op te slaan, met elkaar te communiceren en activiteiten te coördineren. Zookeeper wordt gebruikt in gedistribueerde systemen om gedistribueerde processen en diensten te coördineren. Het biedt een eenvoudig, boomgestructureerd datamodel, een eenvoudige API en een gedistribueerd protocol om de consistentie en beschikbaarheid van gegevens te garanderen. Zookeeper is ontworpen om zeer betrouwbaar en fouttolerant te zijn, en kan een hoge lees- en schrijfdoorvoer aan.
Zookeeper is geïmplementeerd in Java en wordt veel gebruikt in gedistribueerde systemen, met name in het Hadoop-ecosysteem. Het is een Apache Software Foundation-project en wordt uitgebracht onder de Apache-licentie 2.0.
Architectuur van Dierenverzorger
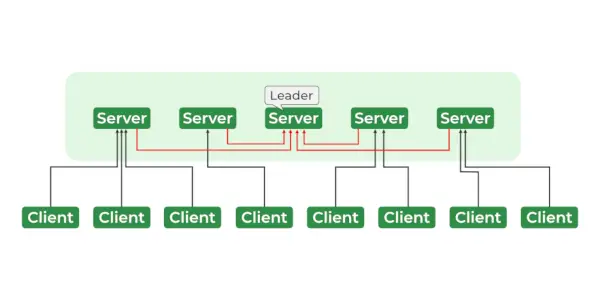
Diensten voor dierenverzorgers
De ZooKeeper-architectuur bestaat uit een hiërarchie van knooppunten, znodes genaamd, georganiseerd in een boomachtige structuur. Elke znode kan gegevens opslaan en heeft een set machtigingen die de toegang tot de znode regelen. De znodes zijn georganiseerd in een hiërarchische naamruimte, vergelijkbaar met een bestandssysteem. Aan de basis van de hiërarchie bevindt zich de root-znode, en alle andere z-knooppunten zijn kinderen van de root-znode. De hiërarchie is vergelijkbaar met een bestandssysteemhiërarchie, waarbij elke znode kinderen en kleinkinderen kan hebben, enzovoort.
Belangrijke componenten in Zookeeper
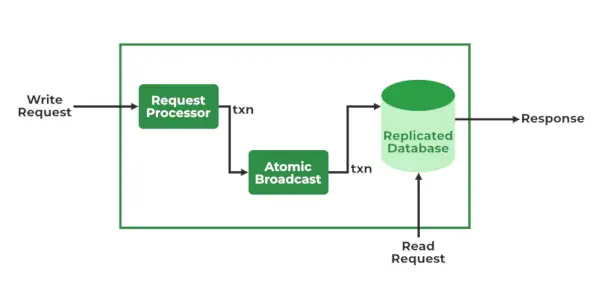
ZooKeeper-diensten
- Leider & Volger
- Verwerker aanvragen – Actief in Leader Node en verantwoordelijk voor het verwerken van schrijfverzoeken. Na verwerking verzendt het wijzigingen naar de volgknooppunten
- Atomaire uitzending – Aanwezig in zowel Leader Node als Follower Nodes. Het is verantwoordelijk voor het verzenden van de wijzigingen naar andere knooppunten.
- Databases in het geheugen (Gerepliceerde databases) -Het is verantwoordelijk voor het opslaan van de gegevens in de dierenverzorger. Elk knooppunt bevat zijn eigen databases. Gegevens worden ook naar het bestandssysteem geschreven, zodat ze kunnen worden hersteld in geval van problemen met het cluster.
Overige onderdelen
- Cliënt – Een van de knooppunten in ons gedistribueerde applicatiecluster. Toegang tot informatie van de server. Elke client stuurt een bericht naar de server om de server te laten weten dat de client leeft.
- Server – Verleent alle diensten aan de klant. Geeft erkenning aan de cliënt.
- Ensemble – Groep Zookeeper-servers. Het minimumaantal knooppunten dat nodig is om een ensemble te vormen is 3.
Dierenverzorger-gegevensmodel
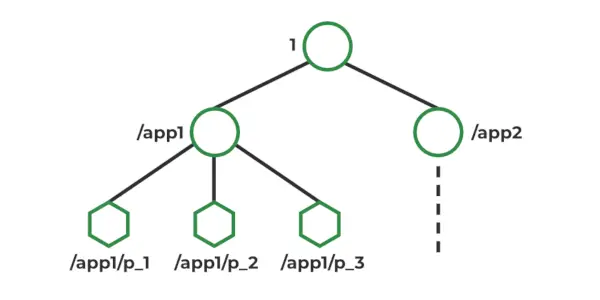
ZooKeeper-gegevensmodel
In Zookeeper worden gegevens opgeslagen in een hiërarchische naamruimte, vergelijkbaar met een bestandssysteem. Elk knooppunt in de naamruimte wordt een Znode genoemd en kan gegevens opslaan en kinderen krijgen. Znodes zijn vergelijkbaar met bestanden en mappen in een bestandssysteem. Zookeeper biedt een eenvoudige API voor het maken, lezen, schrijven en verwijderen van Znodes. Het biedt ook mechanismen voor het detecteren van wijzigingen in de gegevens die zijn opgeslagen in Znodes, zoals horloges en triggers. Znodes onderhouden een statistische structuur die het volgende omvat: versienummer, ACL, tijdstempel, gegevenslengte
Soorten Znodes :
- Vasthoudendheid : Levend totdat ze expliciet worden verwijderd.
- Vluchtig : Actief totdat de clientverbinding actief is.
- Sequentieel : Aanhoudend of kortstondig.
Waarom hebben we ZooKeeper nodig in de Hadoop?
Zookeeper wordt gebruikt voor het beheren en coördineren van de knooppunten in een Hadoop-cluster, inclusief de NameNode, DataNode en ResourceManager. In een Hadoop-cluster helpt Zookeeper bij:
- Configuratie-informatie onderhouden: Zookeeper slaat de configuratie-informatie voor het Hadoop-cluster op, inclusief de locatie van de NameNode, DataNode en ResourceManager.
- Beheer de status van het cluster: Zookeeper houdt de status van de knooppunten in het Hadoop-cluster bij en kan worden gebruikt om te detecteren wanneer een knooppunt defect is of niet meer beschikbaar is.
- Gedistribueerde processen coördineren: Zookeeper kan worden gebruikt om gedistribueerde processen, zoals taakplanning en toewijzing van middelen, over de knooppunten in een Hadoop-cluster te coördineren.
Zookeeper helpt de beschikbaarheid en betrouwbaarheid van een Hadoop-cluster te garanderen door een centrale coördinatieservice te bieden voor de knooppunten in het cluster.
Hoe ZooKeeper in Hadoop werkt?
ZooKeeper werkt als een gedistribueerd bestandssysteem en biedt een eenvoudige set API's waarmee klanten gegevens naar het bestandssysteem kunnen lezen en schrijven. Het slaat zijn gegevens op in een boomachtige structuur, een znode genaamd, die kan worden gezien als een bestand of een map in een traditioneel bestandssysteem. ZooKeeper gebruikt een consensusalgoritme om ervoor te zorgen dat al zijn servers een consistent beeld hebben van de gegevens die zijn opgeslagen in de Znodes. Dit betekent dat als een client gegevens naar een znode schrijft, die gegevens worden gerepliceerd naar alle andere servers in het ZooKeeper-ensemble.
Een belangrijk kenmerk van ZooKeeper is het vermogen om het idee van een horloge te ondersteunen. Met een horloge kan een klant zich registreren voor meldingen wanneer de gegevens die zijn opgeslagen in een znode veranderen. Dit kan handig zijn voor het monitoren van wijzigingen in de gegevens die zijn opgeslagen in ZooKeeper en het reageren op die wijzigingen in een gedistribueerd systeem.
In Hadoop wordt ZooKeeper voor verschillende doeleinden gebruikt, waaronder:
- Configuratie-informatie opslaan: ZooKeeper wordt gebruikt om configuratie-informatie op te slaan die wordt gedeeld door meerdere Hadoop-componenten. Het kan bijvoorbeeld worden gebruikt om de locaties van NameNodes in een Hadoop-cluster of de adressen van JobTracker-knooppunten op te slaan.
- Gedistribueerde synchronisatie bieden: ZooKeeper wordt gebruikt om de activiteiten van verschillende Hadoop-componenten te coördineren en ervoor te zorgen dat ze op een consistente manier samenwerken. Het kan bijvoorbeeld worden gebruikt om ervoor te zorgen dat slechts één NameNode tegelijk actief is in een Hadoop-cluster.
- Naamgeving behouden: ZooKeeper wordt gebruikt om een gecentraliseerde naamgevingsservice voor Hadoop-componenten te onderhouden. Dit kan handig zijn voor het identificeren en lokaliseren van bronnen in een gedistribueerd systeem.
ZooKeeper is een essentieel onderdeel van Hadoop en speelt een cruciale rol bij het coördineren van de activiteiten van de verschillende subcomponenten.
Lezen en schrijven in Apache Zookeeper
ZooKeeper biedt een eenvoudige en betrouwbare interface voor het lezen en schrijven van gegevens. De gegevens worden opgeslagen in een hiërarchische naamruimte, vergelijkbaar met een bestandssysteem, met knooppunten die znodes worden genoemd. Elke znode kan gegevens opslaan en onderliggende znodes hebben. ZooKeeper-clients kunnen gegevens naar deze znodes lezen en schrijven door respectievelijk de methoden getData() en setData() te gebruiken. Hier is een voorbeeld van het lezen en schrijven van gegevens met behulp van de ZooKeeper Java API:
Java
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
mockito wanneer dan ook
>
Sessie en horloges
Sessie
- Verzoeken in een sessie worden uitgevoerd in FIFO-volgorde.
- Zodra de sessie tot stand is gebracht, wordt de sessie-id wordt toegewezen aan de opdrachtgever.
- Klant stuurt hartslagen om de sessie geldig te houden
- sessietime-out wordt meestal weergegeven in milliseconden
Horloges
- Horloges zijn mechanismen waarmee klanten meldingen kunnen ontvangen over de wijzigingen in de Zookeeper
- Cliënt kan meekijken terwijl hij een bepaald znode leest.
- Znodes-veranderingen zijn wijzigingen van gegevens die verband houden met de znodes of veranderingen in de kinderen van de znodes.
- Horloges worden slechts één keer geactiveerd.
- Als de sessie is verlopen, worden horloges ook verwijderd.