Ongeïnformeerd zoeken is een klasse zoekalgoritmen voor algemene doeleinden die met brute kracht werken. Niet-geïnformeerde zoekalgoritmen hebben geen aanvullende informatie over de status of zoekruimte, behalve hoe ze de boom moeten doorkruisen. Daarom wordt dit ook wel blind zoeken genoemd.
Hieronder volgen de verschillende soorten ongeïnformeerde zoekalgoritmen:
1. Zoeken in de breedte:
- Breedte-eerst zoeken is de meest gebruikelijke zoekstrategie voor het doorkruisen van een boom of grafiek. Dit algoritme zoekt in de breedte in een boom of grafiek, daarom wordt het breedte-eerst zoeken genoemd.
- Het BFS-algoritme begint te zoeken vanaf het hoofdknooppunt van de boom en breidt alle volgende knooppunten op het huidige niveau uit voordat het naar knooppunten van het volgende niveau gaat.
- Het breedte-eerst zoekalgoritme is een voorbeeld van een algemeen grafiekzoekalgoritme.
- Breedte-eerst zoeken geïmplementeerd met behulp van de FIFO-wachtrijgegevensstructuur.
Voordelen:
- BFS zal een oplossing bieden als er een oplossing bestaat.
- Als er meer dan één oplossing is voor een bepaald probleem, zal BFS de minimale oplossing bieden die het minste aantal stappen vereist.
Nadelen:
- Het vereist veel geheugen, omdat elk niveau van de boom in het geheugen moet worden opgeslagen om het volgende niveau uit te breiden.
- BFS heeft veel tijd nodig als de oplossing ver verwijderd is van het hoofdknooppunt.
Voorbeeld:
In de onderstaande boomstructuur hebben we het doorlopen van de boom getoond met behulp van het BFS-algoritme van het hoofdknooppunt S naar het doelknooppunt K. Het BFS-zoekalgoritme beweegt zich in lagen, zodat het het pad volgt dat wordt weergegeven door de gestippelde pijl, en de gevolgde pad zal zijn:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
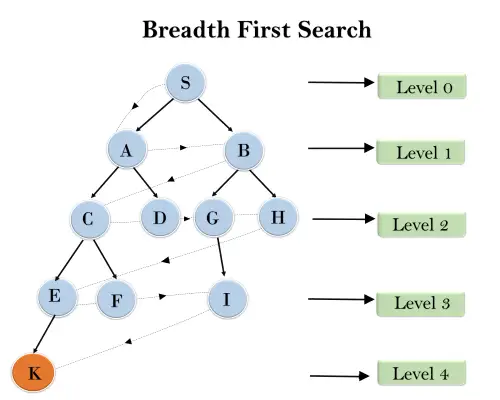
Tijdcomplexiteit: De tijdscomplexiteit van het BFS-algoritme kan worden verkregen door het aantal knooppunten dat in BFS wordt doorlopen tot aan het ondiepste knooppunt. Waar de d = diepte van de ondiepste oplossing en b een knooppunt is in elke toestand.
T(b) = 1+b2+b3+.......+ bD= O (gebD)
Ruimtecomplexiteit: De ruimtecomplexiteit van het BFS-algoritme wordt gegeven door de geheugengrootte van de grens, die O (b is).D).
Volledigheid: BFS is voltooid, wat betekent dat als het ondiepste doelknooppunt zich op een eindige diepte bevindt, BFS een oplossing zal vinden.
Optimaliteit: BFS is optimaal als de padkosten een niet-dalende functie zijn van de diepte van het knooppunt.
2. Diepte eerst zoeken
- Diepte-eerst zoeken is een recursief algoritme voor het doorkruisen van een boom- of grafiekgegevensstructuur.
- Het wordt diepte-eerst zoeken genoemd omdat het begint bij het hoofdknooppunt en elk pad volgt tot het grootste diepteknooppunt voordat het naar het volgende pad gaat.
- DFS gebruikt voor de implementatie een stapelgegevensstructuur.
- Het proces van het DFS-algoritme is vergelijkbaar met het BFS-algoritme.
Opmerking: Backtracking is een algoritmetechniek voor het vinden van alle mogelijke oplossingen met behulp van recursie.
Voordeel:
- DFS vereist heel minder geheugen, omdat het alleen een stapel knooppunten op het pad van het hoofdknooppunt naar het huidige knooppunt hoeft op te slaan.
- Het kost minder tijd om het doelknooppunt te bereiken dan het BFS-algoritme (als het het juiste pad volgt).
Nadeel:
- De mogelijkheid bestaat dat veel toestanden zich blijven herhalen, en er is geen garantie dat de oplossing wordt gevonden.
- Het DFS-algoritme gaat voor diepgaand zoeken en soms gaat het naar de oneindige lus.
Voorbeeld:
In de onderstaande zoekboom hebben we de stroom van diepte-eerst zoeken weergegeven, en deze zal de volgorde als volgt volgen:
Hoofdknooppunt ---> Linkerknooppunt ----> rechterknooppunt.
Het begint te zoeken vanaf het hoofdknooppunt S en doorkruist A, dan B, dan D en E. Nadat het E heeft doorlopen, zal het de boom volgen omdat E geen andere opvolger heeft en het doelknooppunt nog steeds niet is gevonden. Na het teruggaan doorkruist het knooppunt C en vervolgens G, en hier eindigt het als het doelknooppunt is gevonden.

Volledigheid: Het DFS-zoekalgoritme is compleet binnen de eindige toestandsruimte, omdat het elk knooppunt binnen een beperkte zoekboom zal uitbreiden.
Tijdcomplexiteit: De tijdscomplexiteit van DFS zal gelijk zijn aan het knooppunt dat door het algoritme wordt doorlopen. Het wordt gegeven door:
T(n)= 1+ n2+ n3+.........+ znM=O(nM)
Waar, m = maximale diepte van elk knooppunt en dit kan veel groter zijn dan d (ondiepste oplossingsdiepte)
Ruimtecomplexiteit: Het DFS-algoritme hoeft slechts één pad vanaf het hoofdknooppunt op te slaan, daarom is de ruimtecomplexiteit van DFS gelijk aan de grootte van de randset, die O(bm) .
Optimaal: Het DFS-zoekalgoritme is niet optimaal, omdat het een groot aantal stappen of hoge kosten kan genereren om het doelknooppunt te bereiken.
3. Dieptebeperkt zoekalgoritme:
Een in diepte beperkt zoekalgoritme is vergelijkbaar met diepte-eerst zoeken met een vooraf bepaalde limiet. Zoeken met beperkte diepte kan het nadeel van het oneindige pad bij zoeken met diepte eerst oplossen. In dit algoritme wordt het knooppunt op de dieptelimiet behandeld omdat het verder geen opvolgerknooppunten heeft.
Zoeken met beperkte diepte kan worden beëindigd met twee faalvoorwaarden:
- Standaardfoutwaarde: geeft aan dat het probleem geen oplossing heeft.
- Cutoff-foutwaarde: definieert geen oplossing voor het probleem binnen een bepaalde dieptelimiet.
Voordelen:
Zoeken met beperkte diepte is geheugenefficiënt.
Nadelen:
- Dieptebeperkt zoeken heeft ook het nadeel van onvolledigheid.
- Het is mogelijk niet optimaal als het probleem meer dan één oplossing heeft.
Voorbeeld:

Volledigheid: Het DLS-zoekalgoritme is voltooid als de oplossing zich boven de dieptelimiet bevindt.
Tijdcomplexiteit: De tijdscomplexiteit van het DLS-algoritme is O(gebℓ) .
Ruimtecomplexiteit: De ruimtecomplexiteit van het DLS-algoritme is O (b�ℓ) .
Optimaal: Zoeken met beperkte diepte kan worden gezien als een speciaal geval van DFS, en is ook niet optimaal, zelfs niet als ℓ>d.
4. Zoekalgoritme met uniforme kosten:
Zoeken met uniforme kosten is een zoekalgoritme dat wordt gebruikt voor het doorzoeken van een gewogen boom of grafiek. Dit algoritme speelt een rol wanneer voor elke rand verschillende kosten beschikbaar zijn. Het primaire doel van zoeken met uniforme kosten is het vinden van een pad naar het doelknooppunt met de laagste cumulatieve kosten. Zoeken met uniforme kosten breidt knooppunten uit op basis van hun padkosten vanaf het hoofdknooppunt. Het kan worden gebruikt om elke grafiek/boom op te lossen waarbij de optimale kosten gevraagd worden. Een zoekalgoritme met uniforme kosten wordt geïmplementeerd door de prioriteitswachtrij. Het geeft maximale prioriteit aan de laagste cumulatieve kosten. Uniform zoeken naar kosten is equivalent aan het BFS-algoritme als de padkosten van alle randen hetzelfde zijn.
Voordelen:
- Uniforme kostenonderzoek is optimaal omdat bij elke staat het pad met de laagste kosten wordt gekozen.
Nadelen:
- Het maakt niet uit hoeveel stappen er nodig zijn bij het zoeken en maakt zich alleen zorgen over de padkosten. Hierdoor kan dit algoritme vastzitten in een oneindige lus.
Voorbeeld:

Volledigheid:
Het zoeken naar uniforme kosten is voltooid, bijvoorbeeld als er een oplossing is, zal UCS deze vinden.
Tijdcomplexiteit:
Laat C* zijn de kosten van de optimale oplossing , En e is elke stap om dichter bij het doelknooppunt te komen. Dan is het aantal stappen = C*/ε+1. Hier hebben we +1 genomen, omdat we beginnen bij toestand 0 en eindigen bij C*/ε.
Daarom is de tijdscomplexiteit in het slechtste geval van zoeken met uniforme kosten O(geb1 + [C*/e])/ .
Ruimtecomplexiteit:
Dezelfde logica geldt voor ruimtecomplexiteit, dus de worstcaseruimtecomplexiteit van zoeken met uniforme kosten is dat wel O(geb1 + [C*/e]) .
Optimaal:
Zoeken met uniforme kosten is altijd optimaal omdat alleen een pad met de laagste padkosten wordt geselecteerd.
5. Iteratieve verdieping-eerst zoeken:
Het iteratieve verdiepingsalgoritme is een combinatie van DFS- en BFS-algoritmen. Dit zoekalgoritme ontdekt de beste dieptelimiet en doet dit door de limiet geleidelijk te verhogen totdat een doel is gevonden.
Dit algoritme voert een diepte-eerst-zoekopdracht uit tot een bepaalde 'dieptelimiet', en blijft de dieptelimiet na elke iteratie verhogen totdat het doelknooppunt is gevonden.
Dit zoekalgoritme combineert de voordelen van snel zoeken in de breedte en de geheugenefficiëntie van zoeken in de diepte.
Het iteratieve zoekalgoritme is nuttig voor ongeïnformeerd zoeken wanneer de zoekruimte groot is en de diepte van het doelknooppunt onbekend is.
Voordelen:
- Het combineert de voordelen van het BFS- en DFS-zoekalgoritme in termen van snel zoeken en geheugenefficiëntie.
Nadelen:
- Het belangrijkste nadeel van IDDFS is dat het al het werk van de vorige fase herhaalt.
Voorbeeld:
De volgende boomstructuur toont de iteratieve verdieping-eerst-zoekopdracht. Het IDDFS-algoritme voert verschillende iteraties uit totdat het doelknooppunt niet wordt gevonden. De iteratie uitgevoerd door het algoritme wordt gegeven als:

1e iteratie -----> A
2e iteratie ----> A, B, C
3e iteratie ------> A, B, D, E, C, F, G
4e iteratie ------> A, B, D, H, I, E, C, F, K, G
In de vierde iteratie zal het algoritme het doelknooppunt vinden.
Volledigheid:
Dit algoritme is voltooid als de vertakkingsfactor eindig is.
Tijdcomplexiteit:
Laten we aannemen dat b de vertakkingsfactor is en dat de diepte d is, dan is de tijdscomplexiteit in het slechtste geval O(gebD) .
Ruimtecomplexiteit:
De ruimtecomplexiteit van IDDFS zal zijn O(bd) .
Optimaal:
Het IDDFS-algoritme is optimaal als de padkosten een niet-dalende functie zijn van de diepte van het knooppunt.
6. Bidirectioneel zoekalgoritme:
Het bidirectionele zoekalgoritme voert twee gelijktijdige zoekopdrachten uit, één vanuit de initiële status die voorwaarts zoeken wordt genoemd en de andere vanuit het doelknooppunt dat achterwaarts zoeken wordt genoemd, om het doelknooppunt te vinden. Bij bidirectioneel zoeken wordt één enkele zoekgrafiek vervangen door twee kleine subgrafieken waarin de ene begint met zoeken vanaf een initieel hoekpunt en de andere begint vanaf het doelpunt. Het zoeken stopt wanneer deze twee grafieken elkaar kruisen.
Bidirectioneel zoeken kan gebruik maken van zoektechnieken zoals BFS, DFS, DLS, enz.
Voordelen:
- Bidirectioneel zoeken is snel.
- Bidirectioneel zoeken vereist minder geheugen
Nadelen:
- Implementatie van de bidirectionele zoekboom is moeilijk.
Voorbeeld:
In de onderstaande zoekboom wordt een bidirectioneel zoekalgoritme toegepast. Dit algoritme verdeelt één grafiek/boom in twee subgrafieken. Het begint vanaf knooppunt 1 in voorwaartse richting en begint vanaf doelknooppunt 16 in achterwaartse richting.
Het algoritme eindigt bij knooppunt 9, waar twee zoekopdrachten samenkomen.

Volledigheid: Bidirectioneel zoeken is voltooid als we BFS in beide zoekopdrachten gebruiken.
Tijdcomplexiteit: De tijdscomplexiteit van bidirectioneel zoeken met behulp van BFS is O(gebD) .
Ruimtecomplexiteit: De ruimtecomplexiteit van bidirectioneel zoeken is dat wel O(gebD) .
gesorteerde arraylist java
Optimaal: Bidirectioneel zoeken is optimaal.