Python is een geweldige taal voor het uitvoeren van data-analyse, vooral vanwege het fantastische ecosysteem van datacentrisch Python pakketjes. Panda's is een van die pakketten en maakt het importeren en analyseren van gegevens veel eenvoudiger.
Panda's DataFrame mean()
Panda's dataframe.mean() functie retourneert het gemiddelde van de waarden voor de gevraagde as. Als de methode wordt toegepast op een object uit de pandareeks, retourneert de methode een scalaire waarde die de gemiddelde waarde is van alle waarnemingen in de reeks. Panda's-dataframe . Als de methode wordt toegepast op een Pandas Dataframe-object, retourneert de methode a Panda's serie object dat het gemiddelde van de waarden over de opgegeven as bevat.
Syntaxis: DataFrame.mean(axis=0, skipna=True, level=None, numeriek_only=False, **kwargs)
Parameters:
- as: {index (0), kolommen (1)}
- volgorde : Sluit NA/null-waarden uit bij het berekenen van het resultaat
- niveau : Als de as een MultiIndex (hiërarchisch) is, tel dan langs een bepaald niveau en stort in een reeks
- numeriek_alleen: Neem alleen float-, int- en booleaanse kolommen op. Als Geen wordt geprobeerd alles te gebruiken, gebruik dan alleen numerieke gegevens. Niet geïmplementeerd voor serie.
Geeft terug : gemiddelde: serie of dataframe (indien niveau opgegeven)
een array van objecten java
Panda's DataFrame.mean() Voorbeelden
Voorbeeld 1:
Gebruik de functie mean() om het gemiddelde van alle waarnemingen over de indexas te vinden.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 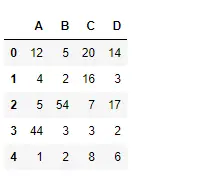
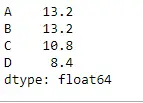
Laten we de functie Dataframe.mean() gebruiken om het gemiddelde over de indexas te vinden.
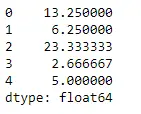
Python # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Uitgang:
Voorbeeld 2:
Gebruik de functie mean() op een dataframe dat geen waarden heeft. Zoek ook het gemiddelde over de kolomas.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Uitgang: