Panda's dataframe.corr() wordt gebruikt om de paarsgewijze correlatie van alle kolommen in het Pandas Dataframe in Python te vinden. Elk NaN waarden worden automatisch uitgesloten. Als u niet-numerieke waarden wilt negeren, gebruikt u de parameter numeriek_only = True. In dit artikel leren we over de DataFrame.corr()-methode in Python .
Pandas DataFrame corr() Methodesyntaxis
Syntaxis: DataFrame.corr(self, method=’pearson’, min_periods=1, numerieke_only = False)
Parameters:
- methode:
- peerson: standaardcorrelatiecoëfficiënt
- kendall: Kendall Tau-correlatiecoëfficiënt
- speerman: Spearman-rangcorrelatie
- min_perioden: Minimaal aantal waarnemingen vereist per paar kolommen om een geldig resultaat te verkrijgen. Momenteel alleen beschikbaar voor Pearson- en Spearman-correlatie
- numeriek_only : Of alleen de numerieke waarden moeten worden bewerkt of niet. Standaard staat deze op False.
Geeft terug: aantal :y : DataFrame
Correlaties van pandagegevens corr() Methode
Een goede correlatie hangt af van het gebruik, maar je kunt gerust zeggen dat je minimaal 0,6 (of -0,6) hebt om van een goede correlatie te spreken. Een eenvoudig voorbeeld om te laten zien hoe correlatie werkt Python .
Python3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Uitvoer
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Voorbeelddataframe maken
Afdrukken van de eerste 10 rijen van het dataframe.
Opmerking: De correlatie van een variabele met zichzelf is 1. Klik op voor een link naar het CSV-bestand Used in Code hier
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Uitvoer

Python Pandas DataFrame corr() Methodevoorbeelden
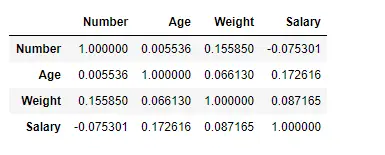
Zoek de correlatie tussen de kolommen met behulp van de Pearson-methode
Hier gebruiken we de functie corr() om de correlatie tussen de kolommen in het dataframe te vinden met behulp van de ‘Pearson’-methode. We hebben slechts vier numerieke kolommen in het Dataframe. Het uitvoerdataframe kan worden geïnterpreteerd alsof voor elke cel de correlatie van de rijvariabele met de kolomvariabele de waarde van de cel is. Zoals eerder vermeld is de correlatie van een variabele met zichzelf 1. Om die reden zijn alle diagonale waarden 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Uitvoer
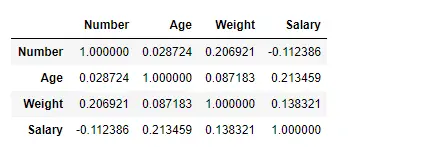
Zoek de correlatie tussen de kolommen met behulp van de Kendall-methode
Gebruik de functie Pandas df.corr() om de correlatie tussen de kolommen in het dataframe te vinden met behulp van de ‘kendall’-methode. Het uitvoerdataframe kan worden geïnterpreteerd alsof voor elke cel de correlatie van de rijvariabele met de kolomvariabele de waarde van de cel is. Zoals eerder vermeld is de correlatie van een variabele met zichzelf 1. Om die reden zijn alle diagonale waarden 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
beperkingen van elektronisch bankieren
>
Uitvoer