- dnorm()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorm()
qnorm(p, mean, sd)>rnorm()
rnorm(n, mean, sd)>waar,
– X vertegenwoordigt de dataset van waarden – gemiddelde(x) vertegenwoordigt het gemiddelde van de dataset X . De standaardwaarde is 0.>– sd(x) vertegenwoordigt de standaardafwijking van de dataset X . De standaardwaarde is 1.>– N is het aantal waarnemingen. – P is een vector van waarschijnlijkheden
Functies om normale verdeling in R te genereren
dnorm()
dnorm()> functie in R-programmering meet de dichtheidsfunctie van de distributie. In de statistieken wordt het gemeten met de onderstaande formule:>waar,
 is gemeen en
is gemeen en 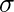 is standaarddeviatie. Syntaxis:
is standaarddeviatie. Syntaxis: dnorm(x, mean, sd)>Voorbeeld:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Uitgang:
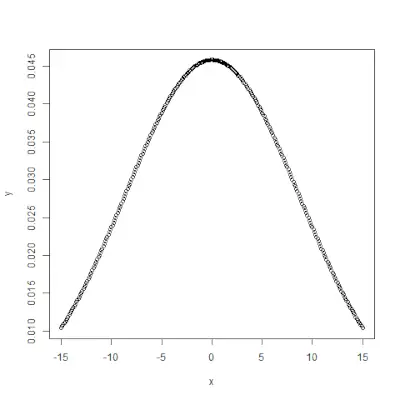
pnorm()
pnorm()> functie is de cumulatieve verdelingsfunctie die de waarschijnlijkheid meet dat een willekeurig getal X een waarde aanneemt die kleiner is dan of gelijk is aan x, dat wil zeggen dat het in de statistieken wordt gegeven door->Syntaxis:
pnorm(x, mean, sd)>Voorbeeld:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Uitgang:
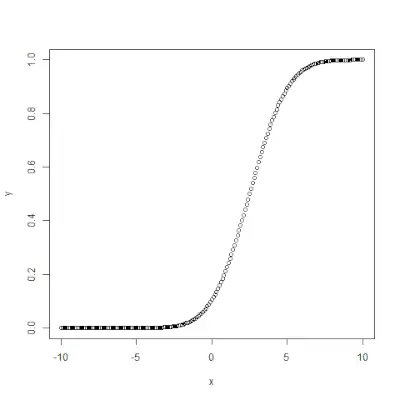
qnorm()
qnorm()> functie is het omgekeerde van pnorm()>functie. Het neemt de waarschijnlijkheidswaarde en geeft uitvoer die overeenkomt met de waarschijnlijkheidswaarde. Het is nuttig bij het vinden van de percentielen van een normale verdeling. Syntaxis: qnorm(p, mean, sd)>Voorbeeld:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Uitgang:
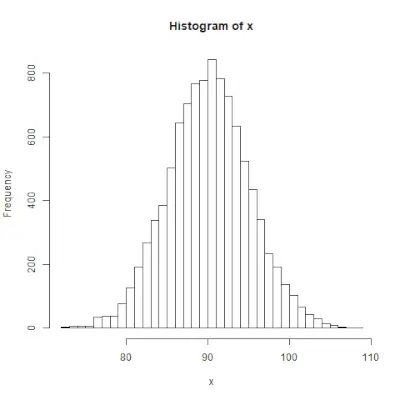
rnorm()
rnorm()> De functie in R-programmering wordt gebruikt om een vector van willekeurige getallen te genereren die normaal verdeeld zijn. Syntaxis: rnorm(x, mean, sd)>Voorbeeld:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Uitgang: