A hash-tabel is een datastructuur die het snel invoegen, verwijderen en ophalen van gegevens mogelijk maakt. Het werkt door een hash-functie te gebruiken om een sleutel toe te wijzen aan een index in een array. In dit artikel zullen we een hashtabel in Python implementeren met behulp van afzonderlijke ketens om botsingen af te handelen.
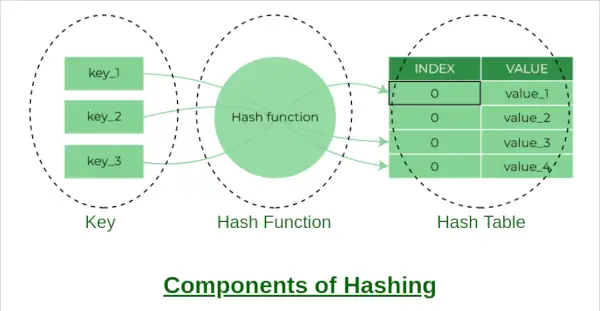
Componenten van hashing
Separate chaining is een techniek die wordt gebruikt om botsingen in een hashtabel af te handelen. Wanneer twee of meer sleutels naar dezelfde index in de array verwijzen, slaan we ze op in een gekoppelde lijst bij die index. Hierdoor kunnen we meerdere waarden in dezelfde index opslaan en ze toch kunnen ophalen met behulp van hun sleutel.
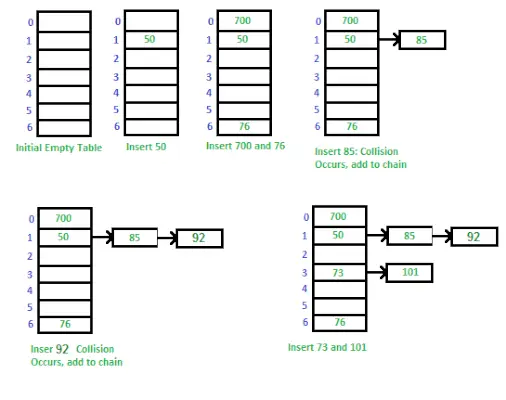
Manier om hashtabel te implementeren met behulp van Separate Chaining
Manier om hashtabel te implementeren met behulp van afzonderlijke ketens:
Maak twee klassen: ‘ Knooppunt ' En ' HashTabel '.
De ' Knooppunt ‘klasse vertegenwoordigt een knooppunt in een gekoppelde lijst. Elk knooppunt bevat een sleutelwaardepaar, evenals een verwijzing naar het volgende knooppunt in de lijst.
Python3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> |
>
>
De klasse ‘HashTable’ bevat de array die de gekoppelde lijsten bevat, evenals methoden voor het invoegen, ophalen en verwijderen van gegevens uit de hashtabel.
Python3
class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> |
>
concat-tekenreeksen java
>
De ' __heet__ ‘methode initialiseert de hashtabel met een bepaalde capaciteit. Het stelt de ‘ capaciteit ' En ' maat ' variabelen en initialiseert de array naar 'Geen'.
De volgende methode is de ‘ _hash ‘methode. Deze methode neemt een sleutel en retourneert een index in de array waar het sleutel-waardepaar moet worden opgeslagen. We zullen de ingebouwde hash-functie van Python gebruiken om de sleutel te hashen en vervolgens de modulo-operator gebruiken om een index in de array te krijgen.
Python3
def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> |
>
>
De ‘invoegen’ methode zal een sleutel-waardepaar in de hashtabel invoegen. Er wordt de index gebruikt waar het paar moet worden opgeslagen met behulp van de ‘ _hash ‘methode. Als er geen gekoppelde lijst bij die index aanwezig is, wordt er een nieuw knooppunt met het sleutel-waardepaar gemaakt en wordt dit als hoofd van de lijst ingesteld. Als er een gekoppelde lijst bij die index aanwezig is, doorloopt u de lijst totdat het laatste knooppunt is gevonden of totdat de sleutel al bestaat, en werkt u de waarde bij als de sleutel al bestaat. Als het de sleutel vindt, wordt de waarde bijgewerkt. Als het de sleutel niet vindt, maakt het een nieuw knooppunt aan en voegt het toe aan de kop van de lijst.
Python3
def> insert(>self>, key, value):> >index>=> self>._hash(key)> >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> |
>
>
De zoekopdracht methode haalt de waarde op die aan een bepaalde sleutel is gekoppeld. Het haalt eerst de index op waar het sleutel-waardepaar moet worden opgeslagen met behulp van de _hash methode. Vervolgens doorzoekt het de gekoppelde lijst bij die index naar de sleutel. Als het de sleutel vindt, retourneert het de bijbehorende waarde. Als het de sleutel niet vindt, roept het a op Sleutelfout .
Python3
arraylist java sorteren
def> search(>self>, key):> >index>=> self>._hash(key)> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> >raise> KeyError(key)> |
>
>
De 'verwijderen' methode verwijdert een sleutelwaardepaar uit de hashtabel. Het haalt eerst de index op waar het paar moet worden opgeslagen met behulp van de ` _hash ` methode. Vervolgens doorzoekt het de gekoppelde lijst bij die index naar de sleutel. Als het de sleutel vindt, wordt het knooppunt uit de lijst verwijderd. Als het de sleutel niet vindt, roept het een ` Sleutelfout `.
Python3
def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> |
>
>
‘__str__’ methode die een tekenreeksrepresentatie van de hashtabel retourneert.
Python3
arraylijst java
def> __str__(>self>):> >elements>=> []> >for> i>in> range>(>self>.capacity):> >current>=> self>.table[i]> >while> current:> >elements.append((current.key, current.value))> >current>=> current.>next> >return> str>(elements)> |
>
>
Hier is de volledige implementatie van de klasse ‘HashTable’:
Python3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> > > class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> > >def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> > >def> insert(>self>, key, value):> >index>=> self>._hash(key)> > >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> > >def> search(>self>, key):> >index>=> self>._hash(key)> > >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> > >raise> KeyError(key)> > >def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> > >def> __len__(>self>):> >return> self>.size> > >def> __contains__(>self>, key):> >try>:> >self>.search(key)> >return> True> >except> KeyError:> >return> False> > > # Driver code> if> __name__>=>=> '__main__'>:> > ># Create a hash table with> ># a capacity of 5> >ht>=> HashTable(>5>)> > ># Add some key-value pairs> ># to the hash table> >ht.insert(>'apple'>,>3>)> >ht.insert(>'banana'>,>2>)> >ht.insert(>'cherry'>,>5>)> > ># Check if the hash table> ># contains a key> >print>(>'apple'> in> ht)># True> >print>(>'durian'> in> ht)># False> > ># Get the value for a key> >print>(ht.search(>'banana'>))># 2> > ># Update the value for a key> >ht.insert(>'banana'>,>4>)> >print>(ht.search(>'banana'>))># 4> > >ht.remove(>'apple'>)> ># Check the size of the hash table> >print>(>len>(ht))># 3> |
>
>Uitvoer
True False 2 4 3>
Tijdcomplexiteit en ruimtecomplexiteit:
- De tijd complexiteit van de invoegen , zoekopdracht En verwijderen methoden in een hashtabel die afzonderlijke ketens gebruiken, zijn afhankelijk van de grootte van de hashtabel, het aantal sleutelwaardeparen in de hashtabel en de lengte van de gekoppelde lijst bij elke index.
- Uitgaande van een goede hashfunctie en een uniforme verdeling van sleutels, is de verwachte tijdscomplexiteit van deze methoden dat ook O(1) voor elke operatie. In het ergste geval kan de tijdscomplexiteit echter groot zijn Op) , waarbij n het aantal sleutelwaardeparen in de hashtabel is.
- Het is echter belangrijk om een goede hashfunctie en een geschikte grootte voor de hashtabel te kiezen om de kans op botsingen te minimaliseren en goede prestaties te garanderen.
- De complexiteit van de ruimte van een hashtabel met behulp van afzonderlijke ketens hangt af van de grootte van de hashtabel en het aantal sleutelwaardeparen dat in de hashtabel is opgeslagen.
- De hashtabel zelf neemt O(m) ruimte, waarbij m de capaciteit van de hashtabel is. Elk gekoppeld lijstknooppunt neemt O(1) spatie, en er kunnen maximaal n knooppunten in de gekoppelde lijsten voorkomen, waarbij n het aantal sleutelwaardeparen is dat in de hashtabel is opgeslagen.
- Daarom is de totale ruimtecomplexiteit gelijk aan O(m + n) .
Conclusie:
In de praktijk is het belangrijk om een geschikte capaciteit voor de hashtabel te kiezen om het ruimtegebruik en de kans op botsingen in evenwicht te brengen. Als de capaciteit te klein is, neemt de kans op botsingen toe, wat prestatieverlies kan veroorzaken. Aan de andere kant, als de capaciteit te groot is, kan de hashtabel meer geheugen in beslag nemen dan nodig is.