In dit artikel zullen we zien hoe u een nieuwe rij waarden aan een bestaand dataframe kunt toevoegen. Dit kan worden gebruikt wanneer we een nieuw item in onze gegevens willen invoegen dat we mogelijk eerder hebben gemist. Er zijn verschillende methoden om dit te bereiken.
Laten we nu met behulp van voorbeelden kijken hoe we dit kunnen doen
Voorbeeld 1:
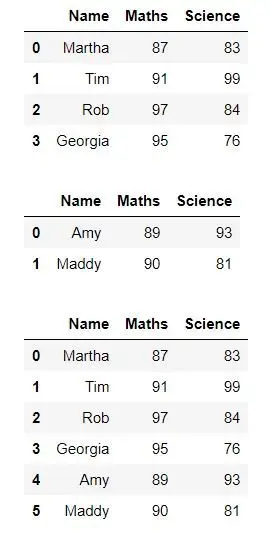
We kunnen een enkele rij toevoegen met DataFrame.loc . We kunnen de rij als laatste in ons dataframe toevoegen. We kunnen het aantal rijen verkrijgen met behulp van len(DataFrame.index) om de positie te bepalen waarop we de nieuwe rij moeten toevoegen.
Python from IPython.display import display, HTML import pandas as pd from numpy.random import randint dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'], 'Maths':[87, 91, 97, 95], 'Science':[83, 99, 84, 76] } df = pd.DataFrame(dict) display(df) df.loc[len(df.index)] = ['Amy', 89, 93] display(df)> Uitgang:
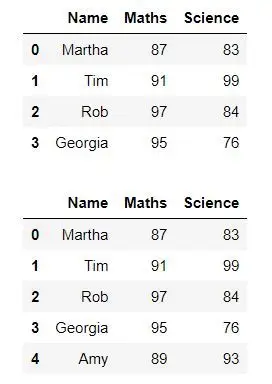
Voorbeeld 2:
We kunnen ook een nieuwe rij toevoegen met behulp van de DataFrame.append() functie
Python from IPython.display import display, HTML import pandas as pd import numpy as np dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'], 'Maths':[87, 91, 97, 95], 'Science':[83, 99, 84, 76] } df = pd.DataFrame(dict) display(df) df2 = {'Name': 'Amy', 'Maths': 89, 'Science': 93} df = df._append(df2, ignore_index = True) display(df) # This code is modified by Susobhan Akhuli> Uitgang:
Voorbeeld 3:
We kunnen ook meerdere rijen toevoegen met behulp van de panda's.concat() door een nieuw dataframe te maken van alle rijen die we moeten toevoegen en dit dataframe vervolgens aan het originele dataframe toe te voegen.
Python from IPython.display import display, HTML import pandas as pd import numpy as np dict = {'Name':['Martha', 'Tim', 'Rob', 'Georgia'], 'Maths':[87, 91, 97, 95], 'Science':[83, 99, 84, 76] } df1 = pd.DataFrame(dict) display(df1) dict = {'Name':['Amy', 'Maddy'], 'Maths':[89, 90], 'Science':[93, 81] } df2 = pd.DataFrame(dict) display(df2) df3 = pd.concat([df1, df2], ignore_index = True) df3.reset_index() display(df3)> Uitgang: