Begeleid en onbewaakt leren zijn de twee technieken van machinaal leren. Maar beide technieken worden in verschillende scenario's en met verschillende datasets gebruikt. Hieronder wordt de uitleg van beide leermethoden gegeven, samen met hun verschillentabel.
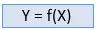
Begeleid machinaal leren:
Supervised learning is een machine learning-methode waarbij modellen worden getraind met behulp van gelabelde gegevens. Bij begeleid leren moeten modellen de mappingfunctie vinden om de invoervariabele (X) in kaart te brengen met de uitvoervariabele (Y).
Bij begeleid leren is toezicht nodig om het model te trainen, wat vergelijkbaar is met het leren van een leerling in aanwezigheid van een leraar. Begeleid leren kan voor twee soorten problemen worden gebruikt: Classificatie En Regressie .
Kom meer te weten Begeleid machinaal leren
Voorbeeld: Stel dat we een afbeelding hebben van verschillende soorten fruit. De taak van ons begeleide leermodel is om de vruchten te identificeren en dienovereenkomstig te classificeren. Om het beeld bij begeleid leren te identificeren, zullen we zowel de inputgegevens als de output daarvoor geven, wat betekent dat we het model zullen trainen op de vorm, grootte, kleur en smaak van elke vrucht. Zodra de training is afgerond, testen we het model door de nieuwe set fruit te geven. Het model identificeert het fruit en voorspelt de opbrengst met behulp van een geschikt algoritme.
Machine learning zonder toezicht:
Ongecontroleerd leren is een andere machine learning-methode waarbij patronen worden afgeleid uit de ongelabelde invoergegevens. Het doel van onbewaakt leren is om de structuur en patronen uit de invoergegevens te vinden. Bij onbegeleid leren is geen toezicht nodig. In plaats daarvan vindt het zelf patronen uit de gegevens.
Kom meer te weten Machine learning zonder toezicht
Onbegeleid leren kan voor twee soorten problemen worden gebruikt: Clustering En Vereniging .
Voorbeeld: Om het leren zonder toezicht te begrijpen, zullen we het hierboven gegeven voorbeeld gebruiken. In tegenstelling tot begeleid leren, zullen we hier dus geen toezicht op het model bieden. We leveren alleen de invoergegevensset aan het model en laten het model de patronen uit de gegevens vinden. Met behulp van een geschikt algoritme zal het model zichzelf trainen en de vruchten in verschillende groepen verdelen op basis van de meest vergelijkbare kenmerken.
De belangrijkste verschillen tussen begeleid en niet-gesuperviseerd leren worden hieronder weergegeven:
| Leren onder toezicht | Ongecontroleerd leren |
|---|---|
| Algoritmen voor begeleid leren worden getraind met behulp van gelabelde gegevens. | Ongecontroleerde leeralgoritmen worden getraind met behulp van ongelabelde gegevens. |
| Het begeleide leermodel gebruikt directe feedback om te controleren of het de juiste output voorspelt of niet. | Een leermodel zonder toezicht accepteert geen feedback. |
| Het begeleide leermodel voorspelt de output. | Een onbewaakt leermodel vindt de verborgen patronen in gegevens. |
| Bij begeleid leren worden inputgegevens samen met de output aan het model geleverd. | Bij onbewaakt leren worden alleen invoergegevens aan het model geleverd. |
| Het doel van begeleid leren is om het model zo te trainen dat het de output kan voorspellen wanneer het nieuwe gegevens krijgt. | Het doel van onbewaakt leren is om de verborgen patronen en nuttige inzichten uit de onbekende dataset te vinden. |
| Begeleid leren heeft begeleiding nodig om het model te trainen. | Voor leren zonder toezicht is geen toezicht nodig om het model te trainen. |
| Begeleid leren kan worden onderverdeeld in Classificatie En Regressie problemen. | Ongesuperviseerd leren kan worden geclassificeerd in Clustering En Verenigingen problemen. |
| Begeleid leren kan worden gebruikt voor die gevallen waarin we zowel de input als de bijbehorende output kennen. | Ongecontroleerd leren kan worden gebruikt voor die gevallen waarin we alleen over invoergegevens beschikken en geen overeenkomstige uitvoergegevens. |
| Het begeleide leermodel levert een nauwkeurig resultaat op. | Het model voor leren zonder toezicht kan minder nauwkeurige resultaten opleveren in vergelijking met leren onder toezicht. |
| Begeleid leren komt niet in de buurt van echte kunstmatige intelligentie, omdat we hierbij eerst het model voor elke gegevens trainen, en pas dan kan het de juiste output voorspellen. | Leren zonder toezicht komt dichter in de buurt van de echte kunstmatige intelligentie, omdat het op dezelfde manier leert als een kind dagelijkse dingen leert door zijn ervaringen. |
| Het bevat verschillende algoritmen zoals lineaire regressie, logistieke regressie, ondersteuningsvectormachine, classificatie met meerdere klassen, beslissingsboom, Bayesiaanse logica, enz. | Het bevat verschillende algoritmen zoals Clustering, KNN en Apriori-algoritmen. |