Een cursor in SQL Server is een d atabase-object waarmee we elke rij tegelijk kunnen ophalen en de gegevens ervan kunnen manipuleren . Een cursor is niets anders dan een verwijzing naar een rij. Het wordt altijd gebruikt in combinatie met een SELECT-instructie. Meestal is het een verzameling van SQL logica die een vooraf bepaald aantal rijen één voor één doorloopt. Een eenvoudige illustratie van de cursor is wanneer we een uitgebreide database met werknemersgegevens hebben en het salaris van elke werknemer willen berekenen na aftrek van belastingen en bladeren.
De SQL-server Het doel van de cursor is om de gegevens rij voor rij bij te werken, te wijzigen of berekeningen uit te voeren die niet mogelijk zijn als we alle records in één keer ophalen . Het is ook handig voor het uitvoeren van administratieve taken zoals back-ups van SQL Server-databases in opeenvolgende volgorde. Cursors worden voornamelijk gebruikt in de ontwikkelings-, DBA- en ETL-processen.
In dit artikel wordt alles uitgelegd over de SQL Server-cursor, zoals de levenscyclus van de cursor, waarom en wanneer de cursor wordt gebruikt, hoe cursors moeten worden geïmplementeerd, de beperkingen ervan en hoe we een cursor kunnen vervangen.
Levenscyclus van de cursor
We kunnen de levenscyclus van een cursor beschrijven in het vijf verschillende secties als volgt:
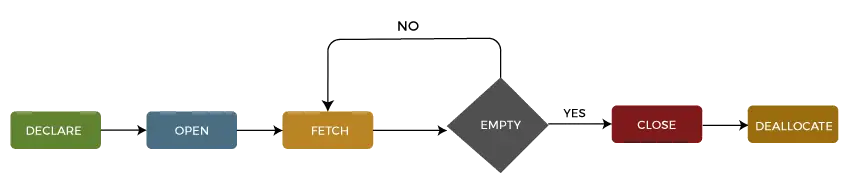
1: Cursor declareren
De eerste stap is het declareren van de cursor met behulp van de onderstaande SQL-instructie:
genezing tool gimp
DECLARE cursor_name CURSOR FOR select_statement;
We kunnen een cursor declareren door de naam ervan op te geven met het gegevenstype CURSOR na het trefwoord DECLARE. Vervolgens schrijven we de SELECT-instructie die de uitvoer voor de cursor definieert.
2: Cursor openen
Het is een tweede stap waarin we de cursor openen om gegevens op te slaan die uit de resultatenset zijn opgehaald. We kunnen dit doen door de onderstaande SQL-instructie te gebruiken:
OPEN cursor_name;
3: Cursor ophalen
Het is een derde stap waarin rijen één voor één of in een blok kunnen worden opgehaald om gegevensmanipulatie uit te voeren, zoals invoeg-, update- en verwijderbewerkingen op de momenteel actieve rij in de cursor. We kunnen dit doen door de onderstaande SQL-instructie te gebruiken:
FETCH NEXT FROM cursor INTO variable_list;
Wij kunnen ook gebruik maken van de @@FETCHSTATUS-functie in SQL Server om de status op te halen van de meest recente FETCH-instructiecursor die tegen de cursor is uitgevoerd. De OPHALEN statement was succesvol toen @@FETCHSTATUS nul uitvoer gaf. De TERWIJL statement kan worden gebruikt om alle records van de cursor op te halen. De volgende code legt het duidelijker uit:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Cursor sluiten
Het is een vierde stap waarin de cursor moet worden gesloten nadat we klaar zijn met werken met een cursor. We kunnen dit doen door de onderstaande SQL-instructie te gebruiken:
CLOSE cursor_name;
5: Cursor ongedaan maken
Het is de vijfde en laatste stap waarin we de cursordefinitie zullen wissen en alle systeembronnen die aan de cursor zijn gekoppeld, vrijgeven. We kunnen dit doen door de onderstaande SQL-instructie te gebruiken:
DEALLOCATE cursor_name;
Gebruik van SQL Server-cursor
We weten dat relationele databasebeheersystemen, waaronder SQL Server, uitstekend zijn in het verwerken van gegevens in een reeks rijen die resultaatsets worden genoemd. Bijvoorbeeld , we hebben een tafel product_tabel waarin de productbeschrijvingen staan. Als we de prijs van het product, dan onderstaande ' UPDATE' query zal alle records bijwerken die voldoen aan de voorwaarde in de ' WAAR' clausule:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Soms moet de applicatie de rijen op een singleton-manier verwerken, d.w.z. rij voor rij, in plaats van het hele resultaat in één keer. We kunnen dit proces uitvoeren door cursors in SQL Server te gebruiken. Voordat we de cursor gebruiken, moeten we weten dat cursors zeer slechte prestaties leveren, dus deze moeten altijd alleen worden gebruikt als er geen andere optie is dan de cursor.
De cursor gebruikt dezelfde techniek als we lussen als FOREACH, FOR, WHILE, DO WHILE gebruiken om in alle programmeertalen één object tegelijk te herhalen. Daarom zou ervoor kunnen worden gekozen omdat het dezelfde logica toepast als het lusproces van de programmeertaal.
Soorten cursors in SQL Server
Hieronder volgen de verschillende soorten cursors in SQL Server:
- Statische cursors
- Dynamische cursors
- Alleen voorwaartse cursors
- Keyset-cursors

Statische cursors
De resultatenset die door de statische cursor wordt weergegeven, is altijd hetzelfde als toen de cursor voor het eerst werd geopend. Omdat de statische cursor het resultaat opslaat tempdb , dat zijn ze altijd alleen lezen . We kunnen de statische cursor gebruiken om zowel vooruit als achteruit te gaan. In tegenstelling tot andere cursors is het langzamer en verbruikt het meer geheugen. Als gevolg hiervan kunnen we het alleen gebruiken als scrollen noodzakelijk is en andere cursors niet geschikt zijn.
Deze cursor toont rijen die uit de database zijn verwijderd nadat deze werd geopend. Een statische cursor vertegenwoordigt geen enkele INSERT-, UPDATE- of DELETE-bewerking (tenzij de cursor wordt gesloten en opnieuw geopend).
Dynamische cursors
De dynamische cursors zijn het tegenovergestelde van de statische cursors waarmee we gegevens kunnen bijwerken, verwijderen en invoegen terwijl de cursor open is. Het is standaard scrollbaar . Het kan alle wijzigingen detecteren die zijn aangebracht in de rijen, volgorde en waarden in de resultatenset, ongeacht of de wijzigingen binnen of buiten de cursor plaatsvinden. Buiten de cursor kunnen we de updates pas zien als ze zijn vastgelegd.
Alleen voorwaartse cursors
Het is het standaard en snelste cursortype onder alle cursors. Het wordt een alleen-voorwaartse cursor genoemd omdat het beweegt alleen vooruit door de resultatenset . Deze cursor ondersteunt geen scrollen. Het kan alleen rijen ophalen van het begin tot het einde van de resultatenset. Hiermee kunnen we invoeg-, update- en verwijderbewerkingen uitvoeren. Hier is het effect van invoeg-, bijwerk- en verwijderbewerkingen die door de gebruiker zijn uitgevoerd en die van invloed zijn op rijen in de resultatenset, zichtbaar wanneer de rijen van de cursor worden opgehaald. Toen de rij werd opgehaald, kunnen we de wijzigingen in de rijen niet via de cursor zien.
De alleen-vooruit-cursors zijn onderverdeeld in drie typen:
- Forward_Only sleutelset
- Vooruit_Alleen statisch
- Snel vooruit

Keyset-gestuurde cursors
Deze cursorfunctionaliteit ligt tussen een statische en een dynamische cursor over het vermogen om veranderingen te detecteren. Het kan niet altijd veranderingen in het lidmaatschap en de volgorde van de resultatenset detecteren, zoals een statische cursor. Het kan veranderingen in de rijwaarden van de resultaatset detecteren als een dynamische cursor. Het kan alleen ga van de eerste naar de laatste en de laatste naar de eerste rij . De volgorde en het lidmaatschap staan vast wanneer deze cursor wordt geopend.
Het wordt beheerd door een reeks unieke identificatiegegevens die hetzelfde zijn als de sleutels in de sleutelset. De sleutelset wordt bepaald door alle rijen die de SELECT-instructie kwalificeerden toen de cursor voor het eerst werd geopend. Het kan ook eventuele wijzigingen in de gegevensbron detecteren, die update- en verwijderbewerkingen ondersteunen. Het is standaard scrollbaar.
Implementatie van voorbeeld
Laten we het cursorvoorbeeld in de SQL-server implementeren. We kunnen dit doen door eerst een tabel te maken met de naam ' klant ' met behulp van de onderstaande verklaring:
voorbeeld van alpha-bèta-snoeien
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Vervolgens voegen we waarden in de tabel in. We kunnen de onderstaande instructie uitvoeren om gegevens aan een tabel toe te voegen:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
We kunnen de gegevens verifiëren door de SELECTEER stelling:
SELECT * FROM customer;
Nadat we de query hebben uitgevoerd, kunnen we de onderstaande uitvoer zien waar we die hebben acht rijen in de tabel:

Nu gaan we een cursor maken om de klantrecords weer te geven. De onderstaande codefragmenten leggen alle stappen van de cursordeclaratie of -creatie uit door alles samen te voegen:
plank honden
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Na het uitvoeren van een cursor krijgen we de onderstaande uitvoer:

Beperkingen van SQL Server-cursor
Een cursor heeft enkele beperkingen, zodat deze altijd alleen mag worden gebruikt als er geen andere optie is dan de cursor. Deze beperkingen zijn:
- Cursor verbruikt netwerkbronnen door elke keer dat een record wordt opgehaald een netwerkretour te vereisen.
- Een cursor is een reeks pointers in het geheugen, wat betekent dat er wat geheugen voor nodig is dat andere processen op onze machine zouden kunnen gebruiken.
- Het legt vergrendelingen op aan een deel van de tabel of de hele tabel bij het verwerken van gegevens.
- De prestaties en snelheid van de cursor zijn langzamer omdat tabelrecords rij voor rij worden bijgewerkt.
- Cursors zijn sneller dan while-loops, maar hebben wel meer overhead.
- Het aantal rijen en kolommen dat in de cursor wordt geplaatst, is een ander aspect dat de cursorsnelheid beïnvloedt. Het verwijst naar hoeveel tijd het kost om uw cursor te openen en een fetch-instructie uit te voeren.
Hoe kunnen we cursors vermijden?
De belangrijkste taak van cursors is om rij voor rij door de tabel te bladeren. Hieronder vindt u de eenvoudigste manier om cursors te vermijden:
Gebruik de SQL while-lus
De eenvoudigste manier om het gebruik van een cursor te vermijden is door een while-lus te gebruiken waarmee een resultaatset in de tijdelijke tabel kan worden ingevoegd.
Door de gebruiker gedefinieerde functies
Soms worden cursors gebruikt om de resulterende rijset te berekenen. We kunnen dit bereiken door een door de gebruiker gedefinieerde functie te gebruiken die aan de vereisten voldoet.
Het gebruik van joins
Join verwerkt alleen die kolommen die aan de opgegeven voorwaarde voldoen en vermindert zo het aantal regels code die snellere prestaties leveren dan cursors voor het geval er grote records moeten worden verwerkt.