Wat is LRU-cache?
Algoritmen voor cachevervanging zijn efficiënt ontworpen om de cache te vervangen wanneer de ruimte vol is. De Minst recent gebruikt (LRU) is een van die algoritmen. Zoals de naam al doet vermoeden wanneer het cachegeheugen vol is, LRU kiest de gegevens die het minst recentelijk zijn gebruikt en verwijdert deze om ruimte te maken voor de nieuwe gegevens. De prioriteit van de gegevens in de cache verandert afhankelijk van de behoefte aan die gegevens, d.w.z. als bepaalde gegevens onlangs worden opgehaald of bijgewerkt, wordt de prioriteit van die gegevens gewijzigd en toegewezen aan de hoogste prioriteit, en neemt de prioriteit van de gegevens af als deze blijft ongebruikte bewerkingen na bewerkingen.
Inhoudsopgave
- Wat is LRU-cache?
- Bewerkingen op LRU-cache:
- Werking van LRU-cache:
- Manieren om LRU-cache te implementeren:
- LRU-cache-implementatie met behulp van wachtrij en hashing:
- LRU-cache-implementatie met behulp van dubbel gekoppelde lijst en hashing:
- LRU-cache-implementatie met Deque & Hashmap:
- LRU-cache-implementatie met behulp van Stack & Hashmap:
- LRU-cache met behulp van Counter Implementation:
- LRU-cache-implementatie met behulp van Lazy Updates:
- Complexiteitsanalyse van LRU-cache:
- Voordelen van LRU-cache:
- Nadelen van LRU-cache:
- Real-World toepassing van LRU-cache:
LRU algoritme is een standaardprobleem en kan afhankelijk van de behoefte variëren, bijvoorbeeld in besturingssystemen LRU speelt een cruciale rol omdat het kan worden gebruikt als algoritme voor paginavervanging om paginafouten te minimaliseren.
hoe Java te upgraden
Bewerkingen op LRU-cache:
- LRUCache (capaciteit c): Initialiseer LRU-cache met een positieve capaciteit C.
- krijgen (sleutel) : Retourneert de waarde van Sleutel ‘ k’ als het aanwezig is in de cache, retourneert het anders -1. Werkt ook de prioriteit van gegevens in de LRU-cache bij.
- zet (sleutel, waarde): Werk de waarde van de sleutel bij als die sleutel bestaat. Voeg anders het sleutel-waardepaar toe aan de cache. Als het aantal sleutels de capaciteit van de LRU-cache overschrijdt, verwijder dan de minst recent gebruikte sleutel.
Werking van LRU-cache:
Laten we aannemen dat we een LRU-cache met capaciteit 3 hebben en dat we de volgende bewerkingen willen uitvoeren:
- Plaats (sleutel=1, waarde=A) in de cache
- Plaats (sleutel=2, waarde=B) in de cache
- Plaats (sleutel=3, waarde=C) in de cache
- Haal (sleutel=2) uit de cache
- Haal (sleutel=4) uit de cache
- Plaats (sleutel=4, waarde=D) in de cache
- Plaats (sleutel=3, waarde=E) in de cache
- Haal (sleutel=4) uit de cache
- Plaats (sleutel=1, waarde=A) in de cache
De bovenstaande bewerkingen worden één voor één uitgevoerd, zoals weergegeven in de onderstaande afbeelding:
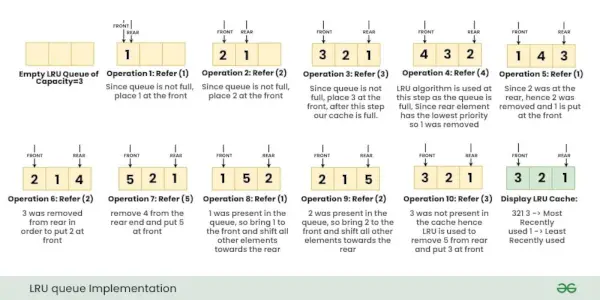
Gedetailleerde uitleg van elke bewerking:
- Zet (sleutel 1, waarde A) : Omdat de LRU-cache een lege capaciteit = 3 heeft, is vervanging niet nodig en plaatsen we {1: A} bovenaan, d.w.z. {1: A} heeft de hoogste prioriteit.
- Zet (sleutel 2, waarde B) : Omdat de LRU-cache een lege capaciteit = 2 heeft, is er opnieuw geen vervanging nodig, maar nu heeft de {2: B} de hoogste prioriteit en wordt de prioriteit van {1: A} verlaagd.
- Zet (sleutel 3, waarde C) : Er is nog steeds 1 lege ruimte vrij in de cache, plaats daarom {3 : C} zonder enige vervanging. Merk op dat de cache nu vol is en de huidige prioriteitsvolgorde van hoog naar laag is {3:C}, {2:B }, {1:A}.
- Verkrijg (sleutel 2) : Retourneer nu de waarde van key=2 tijdens deze bewerking, ook omdat key=2 wordt gebruikt, is de nieuwe prioriteitsvolgorde nu {2:B}, {3:C}, {1:A}
- Verkrijg (sleutel 4): Merk op dat sleutel 4 niet aanwezig is in de cache, we retourneren ‘-1’ voor deze bewerking.
- Zet (sleutel 4, waarde D) : Merk op dat de cache VOLLEDIG is. Gebruik nu het LRU-algoritme om te bepalen welke sleutel het minst recentelijk is gebruikt. Omdat {1:A} de minste prioriteit had, verwijdert u {1:A} uit onze cache en plaatst u {4:D} in de cache. Merk op dat de nieuwe prioriteitsvolgorde {4:D}, {2:B}, {3:C} is
- Zet (sleutel 3, waarde E) : Omdat key=3 al aanwezig was in de cache met waarde=C, zal deze bewerking dus niet resulteren in het verwijderen van een sleutel, maar zal de waarde van key=3 worden bijgewerkt naar ‘ EN' . De nieuwe prioriteitsvolgorde wordt nu {3:E}, {4:D}, {2:B}
- Verkrijg (sleutel 4) : Retourneert de waarde van key=4. De nieuwe prioriteit wordt nu {4:D}, {3:E}, {2:B}
- Zet (sleutel 1, waarde A) : Omdat onze cache VOL is, gebruikt u ons LRU-algoritme om te bepalen welke sleutel het minst recentelijk is gebruikt, en aangezien {2:B} de minste prioriteit had, verwijdert u {2:B} uit onze cache en plaatst u {1:A} in de cache. De nieuwe prioriteitsvolgorde is nu {1:A}, {4:D}, {3:E}
Manieren om LRU-cache te implementeren:
LRU-cache kan op verschillende manieren worden geïmplementeerd, en elke programmeur kan een andere aanpak kiezen. Hieronder vindt u echter veelgebruikte benaderingen:
- LRU met behulp van wachtrij en hashing
- LRU gebruikt Dubbel gekoppelde lijst + hashing
- LRU met behulp van Deque
- LRU met behulp van Stack
- LRU gebruikt Tegenimplementatie
- LRU gebruikt Lazy Updates
LRU-cache-implementatie met behulp van wachtrij en hashing:
We gebruiken twee datastructuren om een LRU-cache te implementeren.
- Wachtrij wordt geïmplementeerd met behulp van een dubbelgekoppelde lijst. De maximale grootte van de wachtrij is gelijk aan het totale aantal beschikbare frames (cachegrootte). De meest recent gebruikte pagina's bevinden zich aan de voorkant en de minst recent gebruikte pagina's aan de achterkant.
- Een hasj met het paginanummer als sleutel en het adres van het corresponderende wachtrijknooppunt als waarde.
Wanneer naar een pagina wordt verwezen, bevindt de gewenste pagina zich mogelijk in het geheugen. Als het zich in het geheugen bevindt, moeten we het knooppunt van de lijst loskoppelen en naar de voorkant van de wachtrij brengen.
Als de gewenste pagina niet in het geheugen aanwezig is, brengen wij die in het geheugen. In eenvoudige woorden: we voegen een nieuw knooppunt toe aan de voorkant van de wachtrij en werken het overeenkomstige knooppuntadres in de hash bij. Als de wachtrij vol is, dat wil zeggen dat alle frames vol zijn, verwijderen we een knooppunt aan de achterkant van de wachtrij en voegen we het nieuwe knooppunt aan de voorkant van de wachtrij toe.
Illustratie:
Laten we eens kijken naar de operaties, Verwijst sleutel X met in de LRU-cache: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Opmerking: Aanvankelijk bevindt er zich geen pagina in het geheugen.Onderstaande afbeeldingen tonen de stapsgewijze uitvoering van de bovenstaande bewerkingen op de LRU-cache.
Algoritme:
- Creëer een klasse LRUCache met een lijst van het type int, een ongeordende kaart van het type
- In de verwijzingsfunctie van LRUCache
- Als deze waarde niet aanwezig is in de wachtrij, duwt u deze waarde voor de wachtrij en verwijdert u de laatste waarde als de wachtrij vol is
- Als de waarde al aanwezig is, verwijdert u deze uit de wachtrij en plaatst u deze vooraan in de wachtrij
- In de weergavefunctie print gebruikt de LRUCache de wachtrij vanaf de voorkant
Hieronder vindt u de implementatie van de bovenstaande aanpak:
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iterator> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->paginanummer = paginanummer;> > >// Initialize prev and next as NULL> >temp->vorige = tijdelijk->volgende = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->aantal = 0;> >queue->voorkant = wachtrij->achterkant = NULL;> > >// Number of frames that can be stored in memory> >queue->aantalOfFrames = aantalOfFrames;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->capaciteit = capaciteit;> > >// Create an array of pointers for referring queue nodes> >hash->array> >= (QNode**)>malloc>(hash->capaciteit *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->array[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->count == wachtrij->aantalFrames;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->achter == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->voorkant == wachtrij->achter)> >queue->voorkant = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->achterkant;> >queue->achter = wachtrij->achter->vorige;> > >if> (queue->achter)> >queue->achter->volgende = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->graaf--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->array[wachtrij->achterkant->paginanummer] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->volgende = wachtrij->voor;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->achter = wachtrij->voor = tijdelijk;> >else> // Else change the front> >{> >queue->voor->vorige = temperatuur;> >queue->voorkant = temperatuur;> >}> > >// Add page entry to hash also> >hash->array[pageNumber] = temp;> > >// increment number of full frames> >queue->tellen++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->array[paginanummer];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->voorkant) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->vorige->volgende = reqPage->volgende;> >if> (reqPage->volgende)> >reqPage->volgende->vorige = reqPage->vorige;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->achter) {> >queue->achter = reqPage->vorige;> >queue->achter->volgende = NULL;> >}> > >// Put the requested page before current front> >reqPage->volgende = wachtrij->voor;> >reqPage->vorige = NULL;> > >// Change prev of current front> >reqPage->volgende->vorige = reqPage;> > >// Change front to the requested page> >queue->voorkant = vereistePagina;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->voorkant->paginanummer);> >printf>(>'%d '>, q->voorkant->volgende->paginanummer);> >printf>(>'%d '>, q->front->volgende->volgende->paginanummer);> >printf>(>'%d '>, q->front->volgende->volgende->volgende->paginanummer);> > >return> 0;> }> |
>
>
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>dubbelWachtrij;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
LRU-cache-implementatie met behulp van dubbel gekoppelde lijst en hashing :
Het idee is heel eenvoudig, d.w.z. blijf de elementen aan de kop invoegen.
- als het element niet aanwezig is in de lijst, voeg het dan toe aan de kop van de lijst
- als het element aanwezig is in de lijst, verplaats het element dan naar de kop en verplaats het resterende element van de lijst
Merk op dat de prioriteit van het knooppunt zal afhangen van de afstand van dat knooppunt tot het hoofd: hoe dichter het knooppunt zich bij het hoofd bevindt, hoe hoger de prioriteit die het heeft. Dus wanneer de cachegrootte vol is en we een element moeten verwijderen, verwijderen we het element dat grenst aan de staart van de dubbel gekoppelde lijst.
LRU-cache-implementatie met Deque & Hashmap:
Deque-datastructuur maakt invoeging en verwijdering van zowel de voorkant als het einde mogelijk. Deze eigenschap maakt de implementatie van LRU mogelijk omdat het Front-element een element met een hoge prioriteit kan vertegenwoordigen, terwijl het eindelement het element met een lage prioriteit kan zijn, dat wil zeggen het minst recent gebruikt.
Werkend:
- Operatie ophalen : Controleert of de sleutel bestaat in de hashkaart van de cache en volgt de onderstaande gevallen op de deque:
- Als de sleutel wordt gevonden:
- Het item wordt beschouwd als recent gebruikt en wordt daarom naar de voorkant van de deque verplaatst.
- De waarde die aan de sleutel is gekoppeld, wordt geretourneerd als resultaat van de
get>operatie.- Als de sleutel niet wordt gevonden:
- return -1 om aan te geven dat een dergelijke sleutel niet aanwezig is.
- Zet bediening: Controleer eerst of de sleutel al bestaat in de hashkaart van de cache en volg de onderstaande gevallen op de deque
- Als de sleutel bestaat:
- De waarde die aan de sleutel is gekoppeld, wordt bijgewerkt.
- Het item is naar de voorkant van de deque verplaatst, omdat het nu het meest recentelijk is gebruikt.
- Als de sleutel niet bestaat:
- Als de cache vol is, betekent dit dat er een nieuw item moet worden ingevoegd en dat het minst recentelijk gebruikte item moet worden verwijderd. Dit wordt gedaan door het item aan het einde van de deque en de bijbehorende vermelding van de hashkaart te verwijderen.
- Het nieuwe sleutel-waarde-paar wordt vervolgens ingevoegd in zowel de hash-kaart als de voorkant van de deque om aan te geven dat dit het meest recent gebruikte item is
LRU-cache-implementatie met behulp van Stack & Hashmap:
Het implementeren van een LRU-cache (Least Recent Used) met behulp van een stapelgegevensstructuur en hashen kan een beetje lastig zijn, omdat een eenvoudige stapel geen efficiënte toegang biedt tot het minst recent gebruikte item. Om dit efficiënt te bereiken, kunt u een stapel echter combineren met een hashkaart. Hier is een aanpak op hoog niveau om het te implementeren:
- Gebruik een hashkaart : De hash-kaart slaat de sleutel-waardeparen van de cache op. De sleutels worden toegewezen aan de overeenkomstige knooppunten in de stapel.
- Gebruik een stapel : De stapel handhaaft de volgorde van de sleutels op basis van hun gebruik. Het minst recent gebruikte item staat onderaan de stapel en het meest recent gebruikte item bovenaan
Deze aanpak is niet zo efficiënt en wordt daarom niet vaak gebruikt.
LRU-cache met behulp van Counter Implementation:
Elk blok in de cache heeft zijn eigen LRU-teller waartoe de waarde van de teller behoort {0 tot n-1} , hier ' N ‘ vertegenwoordigt de grootte van de cache. Het blok dat tijdens blokvervanging wordt gewijzigd, wordt het MRU-blok en als gevolg daarvan wordt de tellerwaarde ervan gewijzigd in n – 1. De tellerwaarden die groter zijn dan de tellerwaarde van het benaderde blok worden met één verlaagd. De overige blokken zijn ongewijzigd.
| Waarde van Conter | Prioriteit | Gebruikte status |
|---|---|---|
| 0 java willekeurig getal | Laag | Minst recent gebruikt |
| n-1 | Hoog | Meest recent gebruikt |
LRU-cache-implementatie met behulp van Lazy Updates:
Het implementeren van een LRU-cache (Least Recent Used) met behulp van luie updates is een veelgebruikte techniek om de efficiëntie van de cachebewerkingen te verbeteren. Bij luie updates wordt de volgorde gevolgd waarin items worden geopend, zonder onmiddellijk de volledige gegevensstructuur bij te werken. Wanneer er een cachemisser optreedt, kunt u op basis van enkele criteria beslissen of u wel of niet een volledige update wilt uitvoeren.
Complexiteitsanalyse van LRU-cache:
- Tijdcomplexiteit:
- Put()-bewerking: O(1), d.w.z. de tijd die nodig is om een nieuw sleutel-waardepaar in te voegen of bij te werken, is constant
- Get()-bewerking: O(1), d.w.z. de tijd die nodig is om de waarde van een sleutel te verkrijgen, is constant
- Hulpruimte: O(N) waarbij N de capaciteit van de cache is.
Voordelen van LRU-cache:
- Snelle toegang : Het kost O(1) tijd om toegang te krijgen tot de gegevens uit de LRU-cache.
- Snelle update : Het kost O(1) tijd om een sleutel-waardepaar in de LRU-cache bij te werken.
- Snelle verwijdering van de minst recent gebruikte gegevens : Er is O(1) nodig om datgene te verwijderen wat niet recentelijk is gebruikt.
- Geen geselen: LRU is minder gevoelig voor pak slaag vergeleken met FIFO, omdat het rekening houdt met de gebruiksgeschiedenis van pagina's. Het kan detecteren welke pagina's vaak worden gebruikt en deze prioriteren voor geheugentoewijzing, waardoor het aantal paginafouten en schijf-I/O-bewerkingen wordt verminderd.
Nadelen van LRU-cache:
- Het vereist een grote cachegrootte om de efficiëntie te vergroten.
- Er moet een aanvullende gegevensstructuur worden geïmplementeerd.
- Hardwareondersteuning is hoog.
- Bij LRU is foutdetectie moeilijk in vergelijking met andere algoritmen.
- Het heeft een beperkte aanvaardbaarheid.
Real-World toepassing van LRU-cache:
- In databasesystemen voor snelle queryresultaten.
- In besturingssystemen om paginafouten te minimaliseren.
- Teksteditors en IDE's om veelgebruikte bestanden of codefragmenten op te slaan
- Netwerkrouters en -switches gebruiken LRU om de efficiëntie van een computernetwerk te vergroten
- Bij compileroptimalisaties
- Hulpmiddelen voor tekstvoorspelling en automatisch aanvullen