Zoals we weten kan het Supervised Machine Learning-algoritme grofweg worden ingedeeld in regressie- en classificatie-algoritmen. In regressie-algoritmen hebben we de uitvoer voor continue waarden voorspeld, maar om de categorische waarden te voorspellen hebben we classificatie-algoritmen nodig.
Wat is het classificatie-algoritme?
Het Classificatie-algoritme is een Supervised Learning-techniek die wordt gebruikt om de categorie van nieuwe observaties te identificeren op basis van trainingsgegevens. Bij classificatie leert een programma van de gegeven dataset of observaties en classificeert vervolgens nieuwe observaties in een aantal klassen of groepen. Zoals, Ja of Nee, 0 of 1, Spam of Geen Spam, kat of hond, enz. Klassen kunnen worden genoemd als doelen/labels of categorieën.
js settime-out
In tegenstelling tot regressie is de uitvoervariabele van Classificatie een categorie en geen waarde, zoals 'Groen of Blauw', 'fruit of dier', etc. Omdat het Classificatie-algoritme een begeleide leertechniek is, zijn er daarom gelabelde invoergegevens nodig, die betekent dat het invoer bevat met de bijbehorende uitvoer.
In het classificatie-algoritme wordt een discrete uitvoerfunctie (y) toegewezen aan invoervariabele (x).
y=f(x), where y = categorical output
Het beste voorbeeld van een ML-classificatie-algoritme is E-mailspamdetector .
Het belangrijkste doel van het classificatie-algoritme is het identificeren van de categorie van een bepaalde dataset, en deze algoritmen worden voornamelijk gebruikt om de output voor de categorische gegevens te voorspellen.
Classificatie-algoritmen kunnen beter worden begrepen met behulp van het onderstaande diagram. In het onderstaande diagram zijn er twee klassen, klasse A en klasse B. Deze klassen hebben kenmerken die op elkaar lijken en niet op andere klassen.
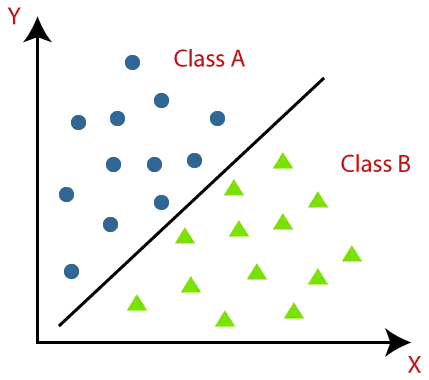
Het algoritme dat de classificatie op een dataset implementeert, staat bekend als een classifier. Er zijn twee soorten classificaties:
Voorbeelden: JA of NEE, MANNELIJK of VROUWELIJK, SPAM of NIET SPAM, KAT of HOND, enz.
Voorbeeld: Classificaties van soorten gewassen, Classificatie van soorten muziek.
Leerlingen met classificatieproblemen:
Bij de classificatieproblemen zijn er twee soorten leerlingen:
Voorbeeld: K-NN-algoritme, casusgebaseerd redeneren
Soorten ML-classificatie-algoritmen:
Classificatie-algoritmen kunnen verder worden onderverdeeld in de voornamelijk twee categorieën:
- Logistieke regressie
- Ondersteuning van vectormachines
- K-dichtstbijzijnde buren
- Kernel-SVM
- Nave Bayes
- Beslisboomclassificatie
- Willekeurige bosclassificatie
Opmerking: we zullen de bovenstaande algoritmen in latere hoofdstukken leren.
Een classificatiemodel evalueren:
Zodra ons model voltooid is, is het noodzakelijk om de prestaties ervan te evalueren; ofwel is het een classificatie- of regressiemodel. Voor het evalueren van een classificatiemodel hebben we dus de volgende manieren:
1. Logverlies of cross-entropieverlies:
- Het wordt gebruikt voor het evalueren van de prestaties van een classificator, waarvan de output een waarschijnlijkheidswaarde tussen 0 en 1 is.
- Voor een goed binair classificatiemodel moet de waarde van logverlies bijna 0 zijn.
- De waarde van logverlies neemt toe als de voorspelde waarde afwijkt van de werkelijke waarde.
- Het lagere logverlies vertegenwoordigt de hogere nauwkeurigheid van het model.
- Voor binaire classificatie kan kruisentropie als volgt worden berekend:
?(ylog(p)+(1?y)log(1?p))
Waarbij y= Werkelijke output, p= voorspelde output.
2. Verwarringsmatrix:
- De verwarringsmatrix biedt ons een matrix/tabel als uitvoer en beschrijft de prestaties van het model.
- Het wordt ook wel de foutenmatrix genoemd.
- De matrix bestaat uit voorspellingen die resulteren in een samengevatte vorm, die een totaal aantal correcte en onjuiste voorspellingen bevat. De matrix ziet er als volgt uit:
| Werkelijk positief | Werkelijk negatief | |
|---|---|---|
| Voorspeld positief | Echt positief | Vals positief |
| Voorspeld negatief | Fout negatief | Echt negatief |

3. AUC-ROC-curve:
prioriteitswachtrij c++
- ROC-curve staat voor Ontvanger Bedieningskarakteristieken Curve en AUC staat voor Gebied onder de curve .
- Het is een grafiek die de prestaties van het classificatiemodel bij verschillende drempels laat zien.
- Om de prestaties van het classificatiemodel met meerdere klassen te visualiseren, gebruiken we de AUC-ROC-curve.
- De ROC-curve wordt uitgezet met TPR en FPR, waarbij TPR (True Positive Rate) op de Y-as en FPR (False Positive Rate) op de X-as.
Gebruik cases van classificatie-algoritmen
Classificatie-algoritmen kunnen op verschillende plaatsen worden gebruikt. Hieronder staan enkele populaire gebruiksscenario's van classificatie-algoritmen:
- Detectie van e-mailspam
- Spraakherkenning
- Identificatie van kankertumorcellen.
- Classificatie van medicijnen
- Biometrische identificatie, enz.